
Tuning ATLAS for jblas
Finally I find some time to recompile the ATLAS libraries for jblas. As it has turned out, the libraries which shipped with jblas 1.2.0 were 30% to 50% slower than what shipped in earlier versions. This still made jblas faster than pure Java implementations, but there are still a lot of FLOPS missing.
To solve this problem once and for all, I did some exhaustive benchmarkings of compiling and running ATLAS on different platforms. I started with 64 bit Linux and the SSE3 settings. I used the following two processors:
- Intel Core i7 M 620 with 2.67 GHz, 4MB Cache
- AMD Opteron 2378 (quad core), 2.39 GHz, 512 KB Cache
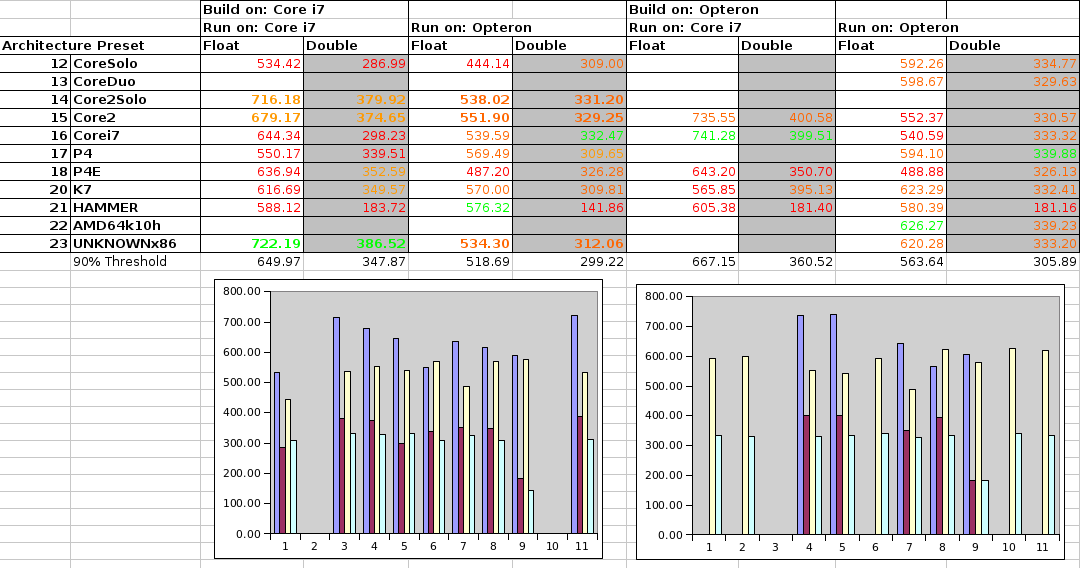
Above are the results for compiling on the i7 or on the Opteron and running on the i7 or the Opteron processor. The numbers shown are relative MFLOPS for large matrix-matrix multiplications (100 would mean 1 floating point operation per clock cycle). The best setting is shown in green, those above 90% of that in orange, and those below in red. Numbers which are missing didn't compile or run.
As you can see, it's really not that easy to pick the best configuration. It's not even the case that the architecture presets for the given platform produce the best results.
If you build on the Core i7, the presets Core2Solo, Core2, and UNKNOWNx86 lead to good performances both on the Core i7 and the Opteron. If you build on the Opteron, there is no preset which gives good results on both processors.
So I think I'll settle on the Core2Solo which will give the following results:
- Core i7:
- single precision: 716.18% (best possible: 741.28%)
- double precision: 379.92% (best possible: 399.51%)
- Opteron
- single precision: 538.02% (best possible: 626.27%)
- double precision: 331.20% (best possible: 339.88%)
To really get the best possible performance, you'd need to use the best possible implementation, but that would mean to inflate the jar even more.
I'm note sure which road to take here. GotoBlas2 has recently been released under a BSD licence and also shows very promising results, which would further increase the number of shared libraries to put in the jar file.
Another option would be to have a central repository with all kinds of libraries, and then you would need to download and install the right one the first time you run jblas. Would that be too bad?
React to this post
Comments (3)
GotoBLAS being open-source now, it should be there, somewhere. If the jars get too inflated, couldn't it be possible to just release different jars for each different implementation? BTW, although "GotoBLAS was made by a hand of God", there are some maintenance efforts out there:
https://github.com/xianyi/O...
http://prs.ism.ac.jp/~nakam...
Hi Santi,
thanks for the links to the GotoBLAS projects.
Having different jars for different platforms might be a possibility, but it's also not without problems. For example, if you are using maven and you have a Mac and a Linux developer on the team, they need to tweak the dependencies to make it work on their machine. Therefore I think it would be better if there would be some installation procedure to put the libraries somewhere.
BTW, do you know of any existing repository of ATLAS or GotoBLAS libraries precompiled for different platforms?
-M
I'm not aware of such repos for pre-compiled versions. The closest I have seen is this "gotoblas for R in win and mac" directory:
http://prs.ism.ac.jp/~nakam...
I always end up going through the compile-yourself headache, so for me, the easiest to create a gotoblas-based jblas.so, the happier. It will be hard to have a jar or a setup process to download the required natives that runs best anywhere - gotoblas can make the task easier, but then someone will decide that MKL is the way to go and waste some more precious hours compiling and testing. It is already nice to have drop-in jars working anywhere with decent performance in most cases, even if it falls to java-land sometimes. I feel that's as far as the "compile once run everywhere" utopia can go here.
I would think it twice for an automatic resolution and download by jblas. I would instead let the users manage that in some more standard way, which wouldn't be so much of a pain for them anyway. For your maven-example use case would actually require little tweaking as compared with the work needed to make sure the user-does-nothing approach works well.