
Twitter in 2011 revamped
We did a little revamp of our NIPS demo "2011 - A year of Twitter". The demo itself was a pure console demo which was nice but not very web friendly.
So we thought about ways to make this data more accessible, and Douwe Osinga (Ex-Googler and currently building of Triposo) came up with the idea to style it after Google trends. So we built trends.twimpact.com. It is basically a searchable interface to the data we've collected.
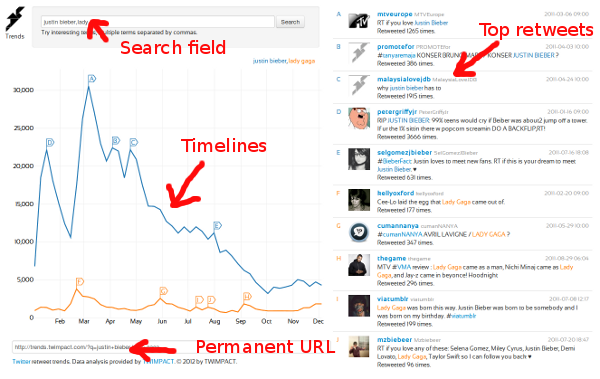
The interface is very simple: You enter search terms (separated by commas) and get the retweet activity for the whole year. On the right, you get the top retweets for the labelled peaks in your data. Below the graph is a text-field which contains the permanent URL for the query, which you can copy and paste to share your findings more easily.
Examples
Here are a few examples (click to go to the website to see the retweets):
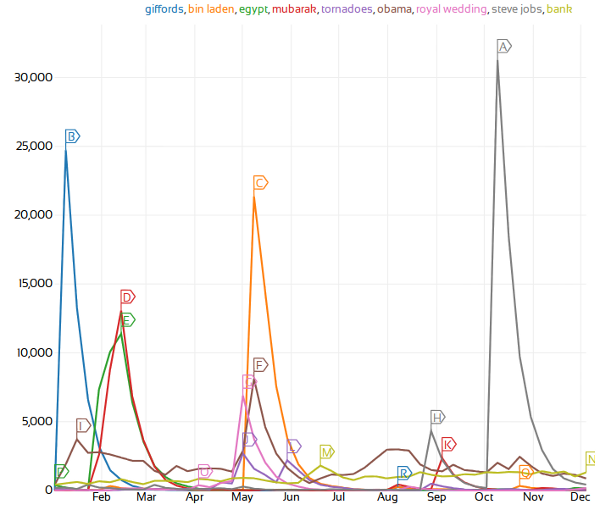
Major events of 2011: Gifford's attempted assassination, the revolution in Egypt, Barack Obama, the royal wedding, Steve Job's death, and the banking crisis. If you click the image, it'll take you to the website itself where you can also see the retweets which are marked.
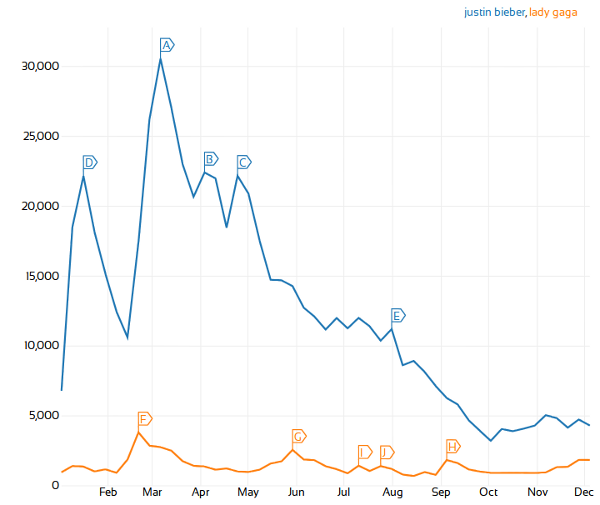
No Twitter analysis is complete without some word on Justin Bieber. Luckily, it seems his influence is on the decline... .
More examples:
- Snow, Tornadoes, and Hurricane: Search terms which have clear seasonal peaks.
- Top movies of 2011: Retweet activity correlates with the box office numbers but probably not as much as you'd expect. Or wouldn't you?
- Credit cards AMEX retweet games and Visa and Mastercard taking heat because they're blocking Wikileaks.
- A year of #fail, a year of LOL
- Mobile OSs Updates and the webOS cancelling.
- Some members of the US women soccer's national team They lost against Japan in the finals, do you remember?
- Holidays in the US
Feel free to add interesting searches below in the discussion section!
Some Background
Some background on the data and the analysis: The data is used from a year of the free Twitter feed, tracking "RT" to get retweets. The free stream is capped at about 50 tweets per second, which still amounts to about 4.3 million tweets per day. The whole raw data for 2011 were about 3.3TB of data (compressed). Using the real-time analysis pipeline we've built for TWIMPACT, we did a full retweet analysis, matching also edited retweets, and extracting trends for all kinds of things. We kept a maximum of three hundred thousand most active retweets in memory. All in all, we saw about 5.4 million distinct retweets during the whole time, retweeted by about 35.8 million users.
Originally, for the NIPS demo we wrote snapshots every 8 hours, resulting in about 1000 historic snapshots. For the current demo, we're using weekly snapshots and converted the original snapshot files to a new format which is based on b-trees giving much faster lookup. There is also a fair amount of caching on several levels.
The full-text index used now is based on Lucene's tokenizer paired with our own language detector to do the proper stemming on a word level.
Note that we're not just looking up the whole timelines for the search terms, but really do a full lookup in the full text index for each term and day, and then combine the retweets found to get the result. Otherwise, we couldn't do queries for more than one search term. So for a search term like "Justin Bieber" this means we're getting a list of all retweets containing the terms "Justin" and "Bieber", computing the intersection, and then summing up the scores.
Right now, there are only the 49 weekly snapshots in there (from beginning of January till just before the NIPS conference), amounting to 14.7 million retweets. Together with the indices, the raw data is about 8.5GB served by a single server. We plan to add current data later on, and then also the daily snapshots.