
Why you don't want real-time analytics to be exact
In case you haven't noticed yet, real-time is pretty big topic in big data right now. The Wikipedia article on big data goes as far as saying that
"Real or near-real time information delivery is one of the defining characteristics of big data analytics."
There article like this one by the Australian Sydney Morning Herald naming real-time as one of the top 6 issues in big data. At this year's BerlinBuzzword conference there were at least four talks talking about real-time.
Now if you look at what people are mostly doing, you see that they are massively scaling out MapReduce or stream processing approaches (as in this blog post on the DataSift infrastructure I've already mentioned before), and/or moving to in-memory (for example GridGain who also seem to be burning through quite a marketing budget right now) to get faster.
Now as I have stated before, I don't believe that scaling can be the ultimate answer, but we also need better algorithms.
At TWIMPACT, we've explored that approach using so-called heavy hitter algorithms from the area of stream mining and found these extremely valuable. Probably their most important property is that they allow you to trade in exactness for speed. This allows you to get started very quickly without having to invest in a data center first just to match the volume of events you have (or do things like deliberately down-sampling which again introduces all kinds of approximation errors).
However, whenever we're talking to people about our approach this is always a hard point to sell. Typical questions were "How can we guarantee that the approximation error is in check?" Or "Isn't big data about having all the data and being able to process it all?"
So here is my top 4 list of reasons why you don't want exact real-time:
Reason 1: Results are changing all the time anyway
First of all, if you have high volume data streams, your statistics will constantly change. So even if you compute exact statistics, the moment you show the result, the true value will already have changed.
Reason 2: You can't have real-time, exactness, and big data
Next, real-time big data is very expensive. As explained very well on slide 24 of this talk by Tom Wilkie, CTO of Acunu, there is something like a "real-time big data triangle of constraints"
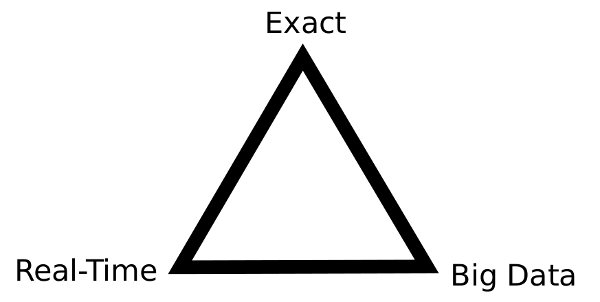
You can have only two: Real-time and Exactness (but no Big Data), Real-Time and Big Data (but no Exactness), or Big Data and Exactness (but not Real-Time). That is, unless you're willing to pay a lot of money.
Reason 3: Exactness is not necessary
Unless you do billing, exact statistics seldom matter. Typical applications for real-time big data analysis like event processing for monitoring are about getting a quick picture of "what's happening". But that means you're only interested in the top most active items in your stream. So it's the ranking that counts and that won't be affected by a small amount of exactness.
Of course, this also depends on the distribution of your data. The worst case for stream mining is data which is uniformly distributed (in the sense that all the events occur with equal probability). But for real world data, this is hardly ever the case. Instead, you have a few "hot" items and a long tail of mostly inactive items which is often of little interest to you.
Reason 4: You already have an exact batch processing system in place
Often, you already have a standard data warehouse which can give you exact numbers if you need them, but you start to get interested in a more real-time view. In that case it doesn't really make sense to spend a fortune on an infrastructure to give you exact results in real-time just to get an idea of what's happening.
Put differently, real-time analyses and standard batch-oriented analyses have quite different roles in your business. Batch-oriented number crunching is done once a month to do the accounting while real-time is used for monitoring. And for that you don't need exact numbers as much as you do for accounting.
React to this post
Comments (6)
As always, an excellent post, Mikio. Although the last assertion of real-time processing only being used in a monitoring perspective might be semi-accurate.
Most of the current so called near-to-real-time systems find it's utility in complex event processing based verticals. For example, fraud detection & prevention, click stream analytics, price optimization, relevance computing, etc. Such systems are augmented with with the ability of either a simple PREDICATE based CCL (Continuous Query Language) or a Bayesian BeliefNet.
Thanks, Chetan. And you're right, I'm oversimplifying a bit, of course. But the general message is that depending on your application you might get away with less than a full blown MapReduce-stack, and I believe it's less often important than people think ;)
You're missing the point! It's not to have exact stats, there's another more important reason.
Realtime reduces and in a lot of cases ELIMINATES the hunting and pecking of searching for information.
It's silly to look at a large dataset, when you're really only interested in correlating much smaller results.
Realtime is important, especially if you use it correctly!
Hi Sam,
thanks for the comment. I'm not quite sure whether we're talking about the same thing, however. I'm mostly referring to situations where you have an event stream which talks about many different items (IP adresses, products on your homepage, etc.), and not just a fixed set of sensors. In these situations, getting to the point where you can extract something meaningful is quite a challenge because you have to analyze quite a large data volume.
Not sure if I got your point, but you seem to be talking about settings where you can do some form of real-time filtering with bounded resources, after which you can dramatically cut down on the amount of data you have to keep and analyze later. But that is something you cannot do easily in the setting I've described above, because whether or not you can eliminate data depends on the relationship between one data point and all the other data (for example, to see that some kind of event happens much more often than all the others.)
So what you refer to "correlating smaller results" is something you would be able to do after crunching a lot of data in real-time first.
Hope that makes my point a bit clearer.
-M
nice post
I am not sure about the stream mining performance of distribution of data, can you explain it more clearly or give some references?
I agree on all of the thoughts you said in your article. It is just good to have an exact analyst that is not permanently at your company because as what it says that exactness is not that kinda necessary.