
Reclaim your data, own a piece of the cloud!
Lately I've been discussing quite a bit with Leo about the current state of the 'Net. Sure it's nice to get all those services in the cloud for free, but in the end, you either have to worry about what exactly happens with your data, or what you can do against companies shutting down cloud based services like the Google Reader, leaving you with a pile of useless XML files, a bit like letting you take home the remnants of your car after compactification.
I used to say that the main problem is that the user is the product, not the customer, but this post by Derek Powazek convinced me that even paying for the service won't ensure that you get decent support and control over your data.
In the end, the only thing that helps is to reclaim your data and the service itself. Just like your wordpress powered blog on your own root server will stay around as long as you pay the bills, both data and the software to make it come alive should run on a computer you control.
But how have ended up in a situation like this anyway? Here is my little history of networked computing.
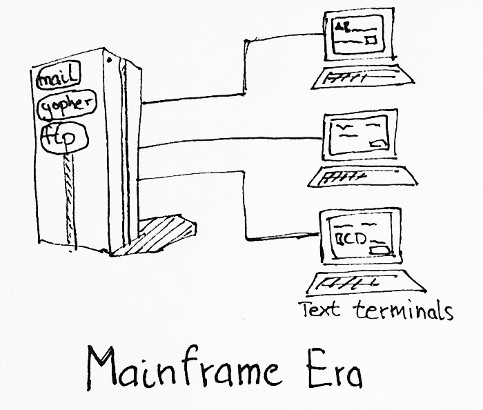
In the mainframe era, computers where huge bulky machines, and only large institutions could afford to have one. People invented time-sharing operating systems to make those computers usable to many people concurrently, which were usually connected through dumb text-terminals. Those terminals mostly worked in a block-oriented manner, meaning that they presented you with a form which you would submit to the server to get the results, a bit like a form on a web page.
Obviously, services where hosted centrally, and you very much depended on the mainframe for storage and providing the service.
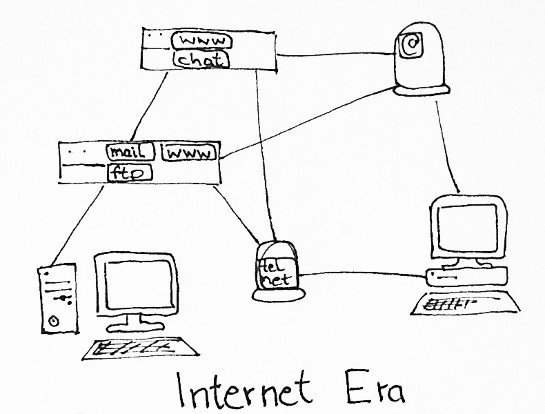
All this changed with the advent of the Internet and the home computer. Instead of a relatively small number of large mainframe computers you got a large network of small machines. Services like mail, ftp, and even http were designed in a way that they could run in a decentralized manner. In principle, anyone could hook up a computer to the network and run the services he was interested on his server.
Of course, you had to solve a number of technical problems, getting good bandwidth to your home was a problem, you had to use a dynamic DNS service to map changing dial-up IP addresses to a DNS entry, you had to know Linux or some other variant of UNIX, but it was possible.
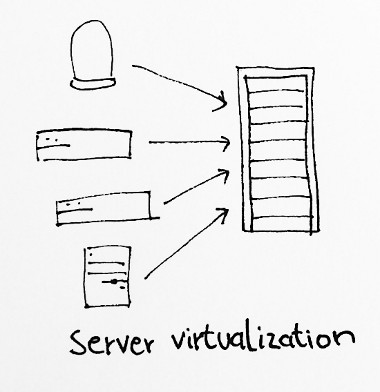
Server virtualization made things a lot easier. People realized that most of the times, computers were sitting idle anyway, so why not combine them virtually in a server. That also made it possible to host a large number of servers in data centers, where they also had constant internet access, for relatively small amounts of money. (BTW, virtualization already existed in the mainframe era.)
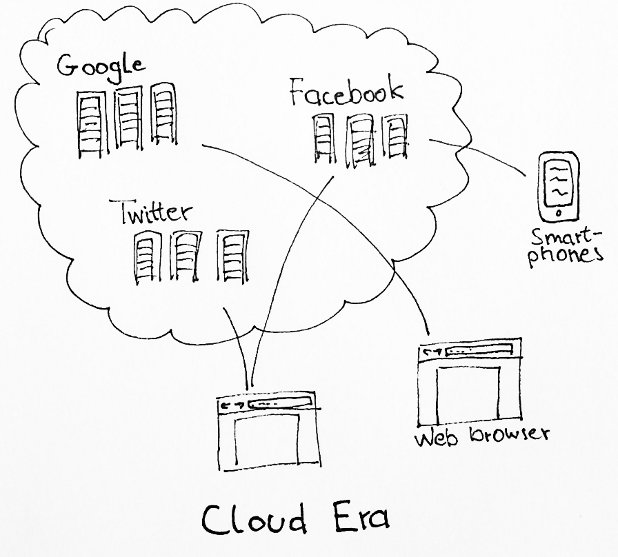
Server virtualization and the resulting technology of putting lots of PC-type servers into racks (which look a lot like the mainframes of old from the outside) allowed companies to create massive server farms for their data intensive services.
It probably all started with Google search and Amazon. Google, because they needed to store an index of the whole web somewhere, Amazon, because millions of people wanted to use the website each day.
Lead by this example, other companies followed, and nowadays it's entirely normal to rent out thousands of servers in the cloud (virtual or otherwise) and build services on that private armada of computers.
I'm not the first to point out that this is really just the same setup like the mainframe era, only with different technological means. While your computer is in principle able to store enormous amounts of data, and it can provide the same services as the machines in the cloud, it's reduced to a screen to run some web browser.
So we went full circle from centralization to decentralization and back, gaining and losing control over our data and the services we need.
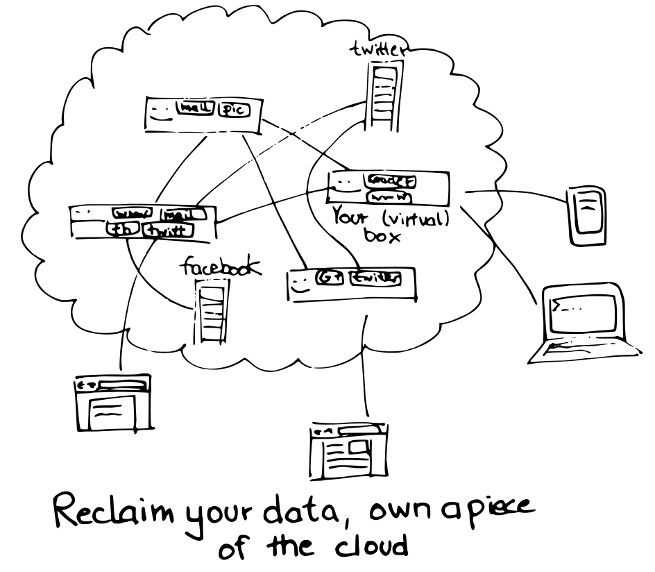
But there is a way out. Now it's easier than ever to rent a piece of the cloud. We already spend enough dollars per month on our smartphones, and probably also for some cloud based services like cloud storage, why not spend a bit more money and also own a small machine somewhere in the cloud?
If that seems odd to you, have you ever noticed that a smartphone is already a bit like a small server in the cloud? It runs Linux (well at least some do), is always connected, comes typically with a few GB of local storage. In principle, you could install some dynamic DNS program on it to become a full Internet server.
Of course, managing virtual machines is still much too technical for the ordinary person. We would also need a new type of cloud based service which would keep only data which needs to be global in the company's server farm while offloading user specific data to the user's servers.
But technically, it's all possible. And wouldn't it be cool? ;)
React to this post
Comments (3)
Hi Mikio,
I can think of few examples that are already going this way:
* Google's http://www.dataliberation.org/ and their Takeout service ( https://www.google.com/take... ). It's only the data (not the services around it), but it's a huge step forward.
* NAS with cloud backup. Files are both on the cloud and on your locally managed disks. The thing is: It's only files, not complex and frequently updated services.
* Dropbox: obviously (you can sync it on any headless linux box). But as before, it's only files. If you decide to go too Google Drive, you can just copy/paste files
Still, most of the current APIs seem to work on the basis of: You can do a lot of things but not retrieve everything.
Maybe replicating would be better than "offloading". In case of a service (or internet) disruption, you could work locally, only missing the global services (the one that are shared between users for instance). If we could have the cloud services available locally, we would have the "perfect" solution (updated services, locally stored data, no network latencies, potentially less downtime, etc.).
And I don't even think that would technically be complicated. On a key value store database, it would be done by example allocating a range of data keys (the Google's Bigtable way) for each client and adding the client's server as a replica of this range. This would be yet an other way to manage data: Sharing it between customers and company directly (not through APIs).
As for the question:
==> It might not be very cool for the non geeks individuals. But for companies, I think it would definitely be a great step forward.
Even if you owned a part of the cloud (which is pretty cool) you wouldn't be able to own the services which leaves you in the same position when Google shuts down Reader or some other service. Who cares if you have the data if you can't use it, right? It might be interesting to see which services people use and which are open source and available to run privately.
Good post. =)
I also think there is really little value in the data you can get from Google. All your data in an XML file, well thank you, what am I going to do with that, then?
Interestingly, in the mean time a few services have stepped in like feedly or digg, and they even seamlessly migrated your data which is nice.
Still I think the best way forward would be to have your own virtual machine somewhere with an app-like interface just like smartphones, so you could actually host and own your own data, and the worst that could happen is that your app is no longer maintained (just as in the ol' days).
That would also make perfect sense for storing and streaming your own music in the cloud, for example.
Ah if I only had the time... ;)