
Three Things About Data Science You Won't Find In the Books
In case you haven't heard yet, Data Science is all the craze. Courses, posts, and schools are springing up everywhere. However, every time I take a look at one of those offerings, I see that a lot of emphasis is put on specific learning algorithms. Of course, understanding how logistic regression or deep learning works is cool, but once you start working with data, you find out that there are other things equally important, or maybe even more.
I can't really blame these courses. I've done years of teaching machine learning at universities, and these lectures always focus very much on specific algorithms. You learn everything about support vector machines, Gaussian mixture models, k-Means clustering, and so on, but only when you work on your master thesis do you learn how to properly work with data.
So what does properly mean anyway? Don't the ends justify the means? Isn't everything ok as long as I get good predictive performance? That is certainly true, but the key is to make sure that you actually get good performance on future data. As I've written elsewhere, it's just too simple to fool yourself into believing your method works when all you are looking at are results on training data.
So here are my three main insights you won't easily find in books.
1. Evaluation Is Key
The main goal in data analysis/machine learning/data science (or however you want to call is), is to build a system which will perform well on future data. The distinction between supervised (like classification) and unsupervised learning (like clustering) makes it hard to talk about what this means in general, but in any case you will usually have some data set collected on which you build and design your method. But eventually you want to apply the method to future data, and you want to be sure that the method works well and produces the same kind of results you have seen on your original data set.
A mistake often done by beginners is to just look at the performance on the available data and then assume that it will work just as well on future data. Unfortunately that is seldom the case. Let's just talk about supervised learning for now, where the task is to predict some outputs based on your inputs, for example, classify emails into spam and non-spam.
If you only consider the training data, then it's very easy for a machine to return perfect predictions just by memorizing everything (unless the data is contradictory). Actually, this isn't that uncommon even for humans. Remember when you were memorizing words in a foreign language and you had to made sure that you were testing the words out of order, because otherwise your brain would just memorize the words based on their order?
Machines with their massive capacity for storing and retrieving large amounts of data can do the same thing easily. This leads to overfitting, and lack of generalization.
So the proper way to evaluate is to simulate the effect that you have future data by splitting the data, training on one part and then predicting on the other part. Usually, the training part is larger, and this procedure is also iterated several times in order to get a few numbers to see how stable the method is. The resulting procedure is called cross-validation.
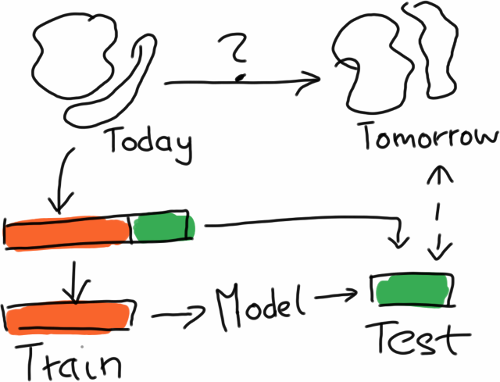 In order to simulate performance on future data, you split the available data in two parts, train on one part, and use the other only for evaluation.
In order to simulate performance on future data, you split the available data in two parts, train on one part, and use the other only for evaluation.
Still, a lot can go wrong, especially when the data is non-stationary, that is, the underlying distribution of the data is changing over time. Which often happens when you are looking at data measured in the real world. Sales figures will look quite different in January than in June.
Or there is a lot of correlation between the data points, meaning that if you know one data point you already know a lot about another data point. For example, if you take stock prices, they usually don't jump around a lot from one day to the other, so that doing the training/test split randomly by day leads to training and test data sets which are highly correlated.
Whenever that happens, you will get performance numbers which are overly optimistic, and your method will not work well on true future data. In the worst case, you've finally convinced people to try out your method in the wild, and then it stops working, so learning how to properly evaluate is key!
2. It's All In The Feature Extraction
Learning about a new method is exciting and all, but the truth is that most complex method essentially perform the same, and that the real difference is made by the way in which raw data is turned into features used in learning.
Modern learning methods are pretty powerful, easily dealing with tens of thousand of features and hundreds of thousand of data points, but the truth is that in the end, these methods are pretty dumb. Especially methods that learn a linear model (like logistic regression, or linear support vector machines) are essentially as dumb as your calculator.
They are really good at identifying the informative features given enough data, but if the information isn't in there, or not representable by a linear combination of input features, there is little they can do. The are also not able to do this kind of data reduction themselves by having "insights" about the data.
Put differently, you can massively reduce the amount of data you need by finding the right features. Hypothetically speaking, if you reduced all the features to the function you want to predict, there is nothing left to learn, right? That is how powerful feature extraction is!
This means two things: First of all, you should make sure that you master one of those nearly equivalent methods, but then you can stick with them. So you don't really need logistic regression and linear SVMs, you can just pick one. This involves also understanding which methods are nearly the same, where the key point lies in the underlying model. So deep learning is something different, but linear models are mostly the same in terms of expressive power. Still, training time, sparsity of the solution, etc. may differ, but you will get the same predictive performance in most cases.
Second of all, you should learn all about feature engineering. Unfortunately, this is more of an art, and almost not covered in any of the textbooks because there is so little theory to it. Normalization will go a long way. Sometimes, features need to be taken the logarithm of. Whenever you can eliminate some degree of freedom, that is, get rid of one way in which the data can change which is irrelevant to the prediction task, you have significantly lowered the amount of data you need to train well.
Sometimes it is very easy to spot these kinds of transformations. For example, if you are doing handwritten character recognition, it is pretty clear that colors don't matter as long as you have a background and a foreground.
I know that textbooks often sell methods as being so powerful that you can just throw data against them and they will do the rest. Which is maybe also true from a theoretical viewpoint and an infinite source of data. But in reality, data and our time is finite, so finding informative features is absolutely essential.
3. Model Selection Burns Most Cycles, Not Data Set Sizes
Now this is something you don't want to say too loudly in the age of Big Data, but most data sets will perfectly fit into your main memory. And your methods will probably also not take too long to run on the data. But you will spend a lot of time extracting features from the raw data and running cross-validation to compare different feature extraction pipelines and parameters for your learning method.
 For model selection, you go through a large number of parameter combinations, evaluating the performance on identical copies of the data.
For model selection, you go through a large number of parameter combinations, evaluating the performance on identical copies of the data.
The problem is all in the combinatorial explosion. Let's say you have just two parameters, and it takes about a minute to train your model and get a performance estimate on the hold out data set (properly evaluated as explained above). If you have five candidate values for each of the parameters, and you perform 5-fold cross-validation (splitting the data set into five parts and running the test five times, using a different part for testing in each iteration), this means that you will already do 125 runs to find out which method works well, and instead of one minute you wait about two hours.
The good message here is that this is easily parallelizable, because the different runs are entirely independent of one another. The same holds for feature extraction where you usually apply the same operation (parsing, extraction, conversion, etc.) to each data set independently, leading to something which is called "embarrasingly parallel" (yes, that's a technical term).
The bad message here is mostly for the Big Data guys, because all of this means that there is seldom the need for scalable implementations of complex methods, but already running the same undistributed algorithm on data in memory in parallel would be very helpful in most cases.
Of course, there exist applications like learning global models from terabytes of log data for ad optimization, or recommendation for million of users, but bread-and-butter use cases are often of the type described here.
Finally, having lots of data by itself does not mean that you really need all the data, either. The questions is much more about the complexity of the underlying learning problem. If the problem can be solved by a simple model, you don't need that much data to infer the parameters of your model. In that case, taking a random subset of the data might already help a lot. And as I said above, sometimes, the right feature representation can also help tremendously in bringing down the number of data points needed.
In summary
In summary, knowing how to evaluate properly can help a lot to reduce the risk that the method won't perform on future data. Getting the feature extraction right is maybe the most effective lever to pull to get good results, and finally, it doesn't always to have Big Data, although distributed computation can help to bring down training times.
I'm contemplating of putting together an ebook with articles like this one and some hands on stuff to get you started with data science. If you want to show your support, you can sign up here to get notified when the book is published.
React to this post
Comments (16)
Any academic references to back up the first paragraph of the second point "It’s All In The Feature Extraction"? I believe in that too, but getting slammed for not being able to provide "adequate" reference
Have a look at https://homes.cs.washington...
Thanks a lot for the reference! I wasn't aware of that article.
Concerning academic references, with research all geared towards finding novel stuff, there is obviously little incentive to say that everything is more or less the same", right? Still, there is implicit evidence, like many different kinds of approaches having comparable performance on many benchmark data sets.
For example, if you look at this website on the MNIST data set you see that all kinds of approaches ranging from neural networks, k-nearest neighbor, decision trees etc. eventually reach good performance. http://yann.lecun.com/exdb/...
Kernel methods (like SVMs) could also be interpreted in the sense that once you have the right kernel, everything can be reduced to linear classification, right?
Besides that, this is something which is well known by everyone who works with data, I guess, or at least every colleague I worked with was aware of this. From an academica perspective, this is of course "cheating" because you are using a priori knowledge where actually you want to find algorithms which can extract that kind of data automatically.
On the other hand, if you look at it from a practical perspective, it also means that typically, there is a lot of potential to improve a method by making sure all the prior knowledge is used to extract good feature.
Hope this helps,
-M
Thank you!
A terrific post covering "real-world" machine learning.
Point 3 on Big Data is a particular peeve as it has been obvious for many years that Big Data reduces to small data if you want do anything that involves machine learning. Wrt log data, most of it is redundant and again reduces to small'ish data. Hopefully, customers will begin to understand before signing-up to expensive "end-to-end" Big Data projects.
Thanks!
Yeah, I also get that a lot from data science people. I still think that Big Data has it's use cases, especially for extracting, or for the cases where you really need to scale out stuff. I think even Spark still looks much too complicated for most people coming from an R/Python background. I'm also not sure if the approach of Spark with MLlib is the right way to approach this, by providing a small set of scalable implementations for algorithms I would typically only use in small to mid-sized settings. I mean k-means clustering on 1TB of data just doesn't make sense. There aren't enough degrees of freedom which would require all that data.
Anyway, an interesting space!
-M
I really agree on the non-necessity of big data. There are many small and medium enterprises that can benefit from machine learning, without involving a cluster to crunch the data.
Also, about the feature extraction paragraph... I believe we will see the automation of that from deep learning algorithms. Their main innovation point is the net being able to self-build the features directly from raw data.
Deep nets perform well with feature extraction on image data, are you aware about any examples on other data types? I haven't so I am a bit skeptical which is the reason for my question.
Hi Roman,
a deep neural net should work on any type of data as soon as you feed it with a vectorized version of the data. The word2vec algorithm is a step in that direction.
A good introduction:
http://deeplearning4j.org/t...
http://deeplearning4j.org/w...
I am skeptical as you are (taht's a good skill for a ML expert), but quite convinced on the ability to work on text with deep learning models. Maybe I would look more into the deep belief models than on convolutional networks... the latter seem too much tied to images in my opinion - I may be wrong.
Piero
I always wondered why a basic research methods class was not taught to ML students. In almost any health care field i can think of a research methods class is taught. The things about samples and tests for generalization are second nature to these students.
When I think of learning I imagine systems that both solicit and elicit data - This sounds like crunching in any approach described to gain intelligent insight on working with the data from an adaptive functional perspective. It is important in how we look at the data and using live learning within focused interest groups, when it comes to spam I think crawlers and detail reporters provide 10 times the amount of info about an email or transmitted data from a high-level perspective beyond the network info itself. Instead of moving on and using existing data, learning algorithms could work with other live and historical info and follow-up with confirmation inquiries on existing -- The method is unknown the base-methods that can be used to build complex methods can be open to a selection system, instead of defining the problem why cant every problem be created within a given scope. I believe bio-centic hardware where the memory is processor and are nano micro that signatures are the way to access the data and it is always live and immediately available without indexing or at least the data that is needed is live, and more data is emerged into living as needed, logical signatures can be established a no-index self hierarchical system given the ability to be anomalous in it's self assessment and creation, hardware need to improve but can be demonstrated across localized systems on a band where they can be monitored in a conventional means.. I am not sure the methods we see as standard or commonly use in Machine Learning application are the defacto form to use. I think the learning process should continue and we should then learn how to harness the learned and processed information in its new forms, I also believe current consumer hardware limits the ability to do this however, it seems that new soft protocol hardware will change this. Data may stream in slow but it can be lit-up and be useful on multiple axis at once. I am waiting to see where it goes, indexing everything makes an extreme load we should begin initializing smart systems and listening to them.
Great article--I like your explanation of the importance of feature engineering. So often people get hung up on learning the latest and greatest machine learning algorithm (plus all of the preceding ones), and don't really think about where the features can be interesting--maybe a lot more interesting than the learning approach. I'll recommend this to my students and post-docs.
@mikio Thought this would be of interest for you - http://thomaswdinsmore.com/....
This article has gotten to the roots in understanding what it is REALLY like, to do data science in the age of 'big data'. Thanks for confirming my suspicions :)
Great To see your post about Data Science and good information can i had seen here for more information you can visit our site. http://www.kellytechno.com/...