The Perpetual Conference
This years ICML conference had an interesting feature: discussion boards for each paper. I’m not sure if they’re the first major machine learning conference to do it, but it’s at least the first one which did a good job of building this and promoting it on the front page.
Instead of using some full discussion board software, they used disqus which is a JavaScript plug-in which can bring discussion threads easily to static sites (and has also been used on this blog for some time now).
Using these pages I could easily interact with Kiri Wagstaff whose paper I discussed in a previous post without actually being at the conference, which is great. It is a good example of how the Internet can help to improve the scientific discourse.
It seems it’s becoming less and less important to actually go to a conference. Talks are recorded, papers are online, and now we have these discussion feeds which are a good substitute for the discussion going on at a poster or after a talk.
We could even compile all these different bits and pieces related to a paper on individual pages to get something like a “perpetual conference.” You don’t actually have to be at the poster session to see what people have been discussing or to ask some clarifying question or pointing out some potential related work, you can do so, even month later over the discussion board.
Of course, I see that there are many benefits of physically hosting a conference. You’re away from your office and can focus on the work which is presented. You meet and interact with people in the hallways which is always nice. On the other hand, flying around half the globe, suffering a jet lag of 6 to 9 hours (at least for us from Europe, it’s often that way) for just a few days, is also quite an investment.
But even for “real” conferences, I think providing this kind of web visibility is a great way to increase the impact of the research presented there. The best thing is that nowadays you don’t even have to do a lot of web programming to get there, but you can instead rely on a huge number of services to tie in what you need using a bit of HTML or JavaScript.
So if you’re organizing a conference or workshop consider making it even more accessible to people not attending:
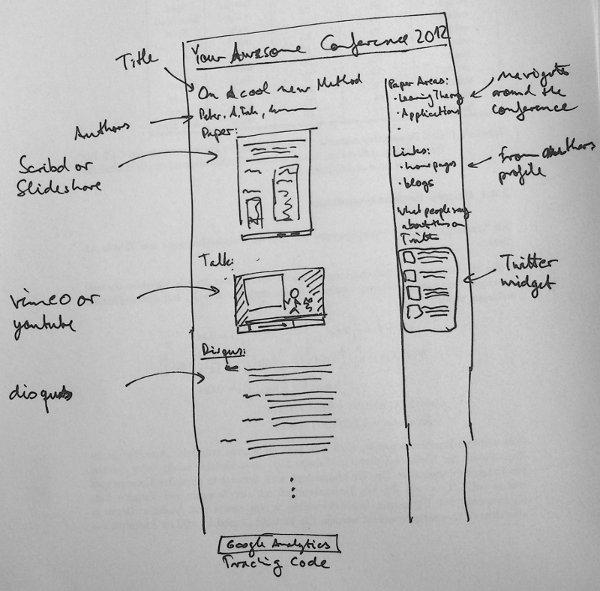
-
Set up individual pages for each of the presentations with permanent URLs.
-
Put the paper up, not only as a PDF, but using a service like slideshare or scribd for easy online viewing.
-
Record the talks, think about streaming the talks as they happen. Put the talks on vimeo or youtube, embed them on your page. If you have the money, pay videolectures to record the talk. They’re really good!
-
Put a discussion thread on the page using a service like disqus.
-
Set up a Twitter account, a Google+ page, or a Facebook page to inform people about what’s happening. Define and promote a Twitter hashtag to go with your conference.
-
Set up a front page for your conference which shows the activities on Twitter and on the discussion forums nicely as they did with this year’s ICML
-
Make sure to install Google analytics or some other form of traffic analysis tool to see what people are responding to.
You may wonder why you should do this, but trust me, it will make you venue much more visible, which is also good for the people who present at your workshop or conference, eventually leading to more citations.
Is Machine Learning Losing Impact?
You’ve probably already heard about the interesting paper by Kiri Wagstaff, titled “Machine Learning that Matters”, presented at this years ICML conference which is just underway in Edinburgh.
The basic argument in her paper is that machine learning might be in danger of losing its impact because the community as a whole has become quite self-referential. People are probably solving real-world problems using ML methods, but there is little sharing of these results within the community. Instead, people focus on existing benchmarks which might have originally had some connection to real-world problems which has been long forgotten, however.
She proposes a number of tasks like $100M solved through ML based decision making or a human life saved through a diagnosis or an intervention recommended by an ML system to get ML back on track.
The paper already generated quite some buzz. There is a heated discussion thread on reddit and many people have responded to it on their blogs, for example, Cheng Soon Ong on the mloss.org blog. I also just found out that she built a website called mlimpact.com which hosts a discussion forum around these topics.
I partly agree with her assessment, however, I think it is wrong to take the main ML conferences and journals as a reference to how much application work is going on. Our group at TU Berlin has always had a strong focus on applications, including neuroscience (in particular brain-computer interfaces), bioinformatics, and computer security, and eventually, you have to start to publish in the conferences and journals of the application field, not in pure ML conferences.
I also think that it is perfectly okay that pure ML is somewhat removed and abstract from real applications. After all, being able to formulate methods abstractly is one of the main reasons there is a discipline like machine learning at all. If everything were always very application specific, it would be very hard to transfer knowledge between people working on different applications.
On the other hand, it is true that there is little return of information from the applications into the pure ML domain, partly because it is very hard to publish application related papers at ML conferences unless they have a significant methodological contribution. I think we’re missing out a lot of interesting insights into the capabilities and limitations of the learning methods we have developed that way.
But I think there are also other problems. The hype around Big Data and Data Science is pretty big right now. As I’ve discussed in a previous post I think machine learners are one of three groups who can potentially contribute a lot to this field (the others being data ming people, and computational statisticians). Still, from talking to my colleagues and other people in ML I get the feeling that we’re losing the race to get our share of the cake, mostly to data mining people who have much better expertise on the technological side, but often lack the methodological depth of machine learners.
I think the main reason why this is happening is that machine learning has been a bit too successful in finding an abstract mathematical language in which to formulate their problems, which mostly statistics and linear algebra. If faced with a concrete problem, the typical machine learner goes through a very painful stage where he tries to get the data, convert it into matrices, cleanse it, so that he can finally load it into matlab, scipy or R. Now he can relax and finally feel at home. Honestly, many of my colleagues consider databases as just another file format, a way to store and retrieve data.
The problem with this, however is that as a data scientist, you also need to be able to put your stuff into production, which means dealing with all kinds of enterprise level technology like web services, databases, messaging middleware, and questions of stability and scalability. Also, as opposed to the batch processing mode which one often uses to get results for papers (load data, grind data for a few hours, write out the results), you have to run your analyses in a much more tightly knit fashion, for example, by hooking up your algorithms to a web services and doing all the communication over a network.
Of course, acquiring this kind of expertise also takes a lot of time, and it’s also not strictly required for an academic career in machine learning. However, in particular for many web related tasks, this is exactly what it takes to make an impact in businesses and on the world for machine learning. Instead, I often get the impression that people consider this extra work as merely “programming”, and something which is outside of the scope of a machine learner.
I’m not sure how to change this. In the end, everyone has to decide for himself what pieces of technology to learn. If you want to apply ML beyond academia, you certainly have to learn about Java, databases, NoSQL, Hadoop, and all this stuff at some point.
Actually, I’m not even convinced that it would make sense to have more technical contributions at core ML conferences. However, I definitely think it should become more common place that you know how to implement an algorithm in an enterprise environment as opposed to a ML-friendly matrix based language such as matlab or R.
So in terms of teaching, I think there is a lot of room for improvement. Students should learn a lot more about how to bridge the gap between a purely mathematical version of an ML algorithm and how you would implement it in the real-world. People have been doing this kind of work at Google, Yahoo, and all the other data driven companies for quite some time, but it’s something different than having students implement SMO in matlab.
Thanks to Johnny D. Edwards for originally telling me about the paper at the Berlin Buzzwords conference.
Talk: Some Introductory Remarks on Bayesian Inference
Some Introductory Remarks on Bayesian Inference
I recently rediscovered these slides from a talk I gave back in 2007 and wanted to share them with you. For those of you who don’t know, Bayesian inference is certain way to approach learning from data and statistical inference. It’s named after Thomas Bayes, an English mathematician who lived in the 18th century.
The main idea (and please be kind with me, I’m not a Bayesian) of Bayes inference is to model your data and your expectations about the data using probability distributions. You write down a so-called generative model for the data, that is, what you expect the distribution of your data to be given its model parameters. Then, if you also specify your prior belief about the distribution of the parameters, you can derive an updated distribution over your parameters given observed data.
Bayesian inference has been applied to the whole range of inference problems, ranging from classification to regression to clustering, and beyond. The main inference step sketched above involves integrating (as in $\int f(x) dx$, not as in continuous integration ;)) over the parameter space which is numerically intractable for most complex distributions. Therefore, Bayesian inference often relies on techniques used in numerical integration like Markov chain Monte Carlo-Methods, Gibbs sampling, or other kinds of approximations like Variational Bayes, which is related to mean-field approximations used in statistical physics.
There is a very silly (at least IMHO) divide within the field of statistics between Frequentists and Bayesians which I’ve discussed elsewhere.
In any case, the slides above discuss the very basics: Bayes rule, the role of the prior, the concept of conjugancy (combinations of model assumptions and priors which can be solved exactly, that is without requiring numerical integration) and pseudo-counts, and a bit of discussion on the Frequentism vs. Bayesian divide.