
Big Data beyond MapReduce: Google's Big Data papers
Mainstream Big Data is all about MapReduce, but when looking at real-time data, limitations of that approach are starting to show. In this post, I'll review Google's most important Big Data publications and discuss where they are (as far as they've disclosed).
MapReduce, Google File System and Bigtable: the mother of all big data algorithms
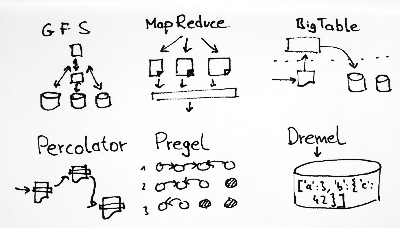
Chronologically the first paper is on the Google File System from 2003, which is a distributed file system. Basically, files are split into chunks which are stored in a redundant fashion on a cluster of commodity machines (Every article about Google has to include the term "commodity machines"!)
Next up is the MapReduce paper from 2004. MapReduce has become synonymous with Big Data. Legend has it that Google used it to compute their search indices. I imagine it worked like this: They have all the crawled web pages sitting on their cluster and every day or so they ran MapReduce to recompute everything.
Next up is the Bigtable paper from 2006 which has become the inspiration for countless NoSQL databases like Cassandra, HBase, and others. About half of the architecture of Cassandra is modeled after BigTable, including the data model, SSTables, and write-ahead-logs (the other half being Amazon's Dynamo database for the peer-to-peer clustering model).
Percolator: Handling individual updates
Google didn't stop with MapReduce. In fact, with the exponential growth of the Internet, it became impractical to recompute the whole search index from scratch. Instead, Google developed a more incremental system, which still allowed for distributed computing.
Now here is where it's getting interesting, in particular compared to what common messages from mainstream Big Data are. For example, they have reintroduced transactions, something NoSQL still tells you that you don't need or cannot have if you want to have scalability.
In the Percolator paper from 2010, they describe how the Google is keeping its web search index up to date. Percolator is built on existing technologies like Bigtable, but adds transactions and locks on rows and tables, as well as notifications for change in the tables. These notifications are then used to trigger the different stages in a computation. This way, the individual updates can "percolate" through the database.
This approach is reminiscent of stream processing frameworks (SPFs) like Twitter's Storm, or Yahoo's S4, but with an underlying data base. SPFs usually use message passing and no shared data. This makes it easier to reason about what is happening, but also has the problem that there is no way to access the result of the computation unless you manually store it somewhere in the end.
Pregel: Scalable graph computing
Eventually, Google also had to start mining graph data like the social graph in an online social network, so they developed Pregel, published in 2010.
The underlying computational model is much more complex than in MapReduce: Basically, you have worker threads for each node which are run in parallel iteratively. In each so-called superstep, the worker threads can read messages in the node's inbox, send messages to other nodes, set and read values associated with nodes or edges, or vote to halt. Computations are run till all nodes have voted to halt. In addition, there are also Aggregators and Combiners which compute global statistics.
The paper shows how to implement a number of algorithms like Google's PageRank, shortest path, or bipartite matching. My personal feeling is that Pregel requires even more rethinking on the side of the implementor than MapReduce or SPFs.
Dremel: Online visualizations
Finally, in another paper from 2010, Google describes Dremel, which is an interactive database with an SQL-like language for structured data. So instead of tables with fixed fields like in an SQL database, each row is something like a JSON object (to be more exact, the data is modeled by Google's protocol buffer format which imposes restrictions on what fields are allowed). Internally, data is stored in a special format which makes sweeps through the data very efficient. Queries are pushed down to servers and then aggregated on their way back up and use some clever data format for maximum performance.
Big Data beyond MapReduce
Google didn't stop with MapReduce, but they developed other approaches for applications where MapReduce wasn't a good fit, and I think this is an important message for the whole Big Data landscape. You cannot solve everything with MapReduce. You can make it faster by getting rid of the disks and moving all the data to in-memory, but there are tasks whose inherent structure makes it hard for MapReduce to scale.
Open source projects have picked up on the more recent ideas and papers by Google. For example, Apache Drill is reimplementing the Dremel framework, while projects like Apache Giraph and Stanford's GPS are inspired by Pregel.
There are still other approaches as well. I'm personally a big fan of stream mining (not to be confused with stream processing) which aims to process event streams with bounded computational resources by resorting to approximation algorithms. Noel Welsh has some interesting slide's on the topic.
Related posts:
- One does not simply scale into real-time
- Announcing streamdrill
- More Google Big Data papers: Megastore and Spanner
Edits: Feb 25, 2013 Clarified the Text on Dremel a bit based on Dmitriy Belenko's comments, corrected post time.
Mar 12, 2013 Added link to follow-up post.
React to this post
Comments (11)
"You cannot solve everything with MapReduce" - go wash your mouth with soap!
Writing mapreduces always reminds me of the old saying, if you have a hammer, everything looks like a nail.
Yeah ;)
For actor-based concurrency, I get the same feeling.
One should measure the extent to which a certain abstraction turns everything into a hammer then "hammerness" or "hammericity" of it ;) Am 22.02.2013 18:43 schrieb "Disqus" <notifications@disqus.net>:
Seems like great minds think alike, I just blogged a very similar post a few weeks ago: http://datacommunitydc.org/...
Thanks for the link! I see you also covered Spanner, I'll edit my post to add it now.
Great blog. Can you please add RSS feed to it ?
@MickeyMGafny
There already is one: http://feeds.feedburner.com...
So is Big Table like an implementation of BigData?
Big Table was like the first big distributed NoSQL database, but not really Big Data. The Map Reduce paper is probably the starting point of Big Data.
You can write about what google is thinking next, what is their next research paper ?
No idea what they're working on next. They usually publish those papers years after they've built the systems. The latest on which got quite some attention was this one on the algorithms behind adwords: http://research.google.com/...
Hi sir can u suggest me sm new technologies topics fr my mtech project n seminars example like cloud