
Stream Processing has no Query Layer
When it comes to real-time big data, stream processing frameworks are an interesting alternative to MapReduce. Instead of storing and crunching data in batches, they process the data as it comes along, which immediately makes much more sense if you're dealing with event streams. Frameworks like Twitter's Storm and Yahoo's S4 allow you to scale such computations. Similar to MapReduce jobs, you specify small worker threads which are then deployed and monitored automatically to provide robust scalability.
So at first you may think "stream processing is basically MapReduce for events", but there is an important and significant difference: There is no query layer in stream processing (well at least, there isn't in Storm and S4).
With query layer, I mean the capability to query the results of your computations. For stream processing, in particular, this means while the computations are still running, because you are typically consuming a never-ending stream of new events.
For example, if we consider the ubiquituous word count example, where you pipe in some constant stream of sentences (let's say, tweets), how can you query the counts for a given word at a given time?
The answer is a bit surprising to most people I've talked to: There is no way you can query the result (at least from within the stream processing framework). The information is there, distributed over numerous worker thread who all see and process a part of the stream, but there is no way to access that information. Instead, results have to be periodically output, either to screen or to some persistent storage.
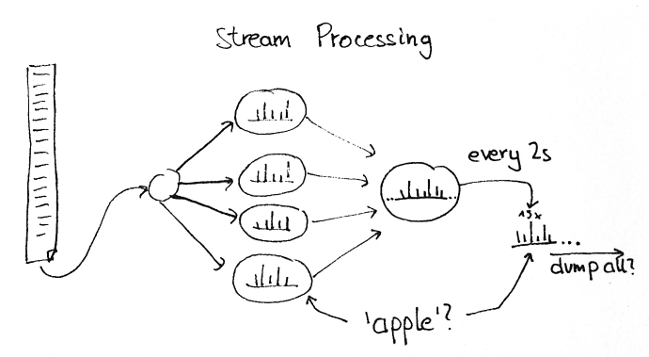
Now these are only toy examples, of course, but it also means that for real-world applications, you need some database backend to store your results. Depending on the amount of data you process and the level of aggregation you do (or don't do), this also means that your stock MySQL won't suffice to keep up with your stream processing cluster.
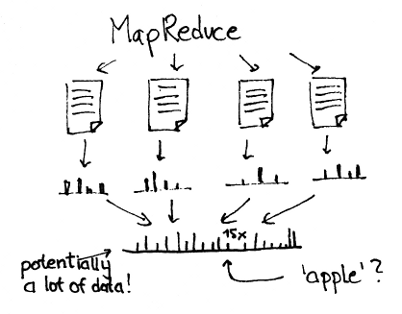
The same can be said of MapReduce jobs which run periodically to update some statistics, but the difference is that MapReduce doubles as the storage solution while you need an additional backend for stream processing.
So I think stream processing is good when:
- you have a high frequency event stream,
- have to do quite complex analyses on each event independently,
- do a lot of aggregation so that there is a huge reduction in data volume.
But it's not generally applicable when:
- you need to do a lot of persistent updates which each event,
- need to query results while the analysis is still ongoing.
Let me know if I'm wrong. I'd be interested in learning about some real-world experiences with scaling stream processing!
_Edit, Sep 6, 2013:_Shortly after the post I learned about an interesting post by Michael Noll where he explains in detail how to do topic trending over rolling windows with Storm. The implementation shows exactly the level of complexity I was showing above, in particular the need to aggregate trends from the different counter worker threads, and that you can only get the trends if you emit them, and potentially store them somewhere to be queried later.
React to this post
Comments (4)
What's wrong with persistent updates?
Hi EJ,
nothing per se, but need a backend which can keep up with the volume of updates. So if you process 100k events per second, you need a database which can handle that. Which means the stream processing framework is not sufficient, you also need to scale the database. Which is kinda bad because it adds a lot of complexity and cost.
Hope this helps to clarify,
-M
interesting post! my 2 cents: I use Storm to compute some statistics on twitter and I usually have intermediate results stored on Redis from independent bolts. It works nicely when the stream is below ~100 tps (tweets per second), then the latency starts to be a bit high affecting the whole computation. I introduced an intermediate queue between storm and redis, with a custom process which dequeue from the queue and updates redis independently from storm. This solution scales simply adding more processes writing to Redis. Obviously the tradeoff is that there's no guarantee that the last result available on REDIS is really the latest computed.
what do you think?
Hi Davide,
thanks for sharing. Did I read that right, 100 tweets per second? (or 100k? ;)) But I think your setup nicely describes what I was explaining in the post: You need to have some persistent backend and making that scale can be quite a challenge.
You also point out another issue I hadn't been considering yet: If you use a scalable persistent storage solution like existing NoSQL solutions, you might end up with partially committed writes when something breaks, because you have no support for transactions.
I've been thinking a bit more about this and what would be nice is if there actually was a way to query the information stored in all those worker threads. You can probably build something like this by hand, either externally to the stream processing framework, or by injecting query events into the data event stream, but it would be nicer if support came out of the box.
-M