
Big Data & Machine Learning Convergence
I recently had two pretty interesting discussions with students here at TU Berlin which I think are representative with respect to how big the divide between the machine learning community and the Big Data community still is.
Linear Algebra vs. Functional collections
One student is working on implementing a boosting method I wrote a few years ago using next-gen Big Data frameworks like Flink and Spark as part of his master thesis. I choose this algorithm because it the operations involved were quite simple: computing scalar products, vector differences, and norms of vectors. Probably the most complex thing is to compute a cumulative sum.
These are all operations which boil down to linear algebra, and the whole algorithm is a few lines of code in pseudo-notation expressed in linear algebra. I was wondering just how hard it would be to formulate this using a more "functional collection" style API.
For example, in order to compute the squared norm of a vector, you have to square each element and sum them up. In a language like C you'd do it like this:
{% highlight c++ %} double squaredNorm(int n, double a[]) { double s = 0; for(i = 0; i < n; i++) { s += a[i] * a[i]; } return s; } {% endhighlight %}
In Scala, you'd express the same thing with
def squaredNorm(a: Seq[Double]) =
a.map(x => x*x).sum
In a way, the main challenge here consists in breaking down these for-loops into these sequence primitives provided by the language. Another example: the scalar product (sum of product of the corresponding elements of two vectors) would become
def scalarProduct(a: Seq[Double], b: Seq[Double]) =
a.zip(b).map(ab => ab._1 * ab._2).sum
and so on.
Now turning to a system like Flink or Spark which provides a very similar set of operations and is able to distribute them, it should be possible to use a similar approach. However, the first surprise was that in distributed systems, there is no notion of order of a sequence. It's really more of a collection of things.
So if you have to compute the scalar product between the vectors, you need to extend the stored data to include the index of each entry as well, and then you first need to join the two sequences on the index to be able to perform the map.
The student is still half way through with this, but already it has cost considerable amount of mental work to rethink standard operations in the new notation, and most importantly, have faith in the underlying system that it is able to perform things like joining vectors such that elements are aligned in a smart fashion.
I think the main message here is that machine learners really like to think in terms of matrices and vectors, not so much databases and query languages. That's the way algorithms are described in papers, that's the way people think, and the way people are trained, and it would be tremendously helpful if there is a layer for that on top of Spark or Flink. There are already some activites in that direction like distributed vectors in Spark or the spark-shell in Mahout, and I'm pretty interested to see whether how they will develop.
Big Data vs. Big Computation
The other interesting discussion was with a Ph.D. student who works on predicting properties in solid state physics using machine learning. He apparently didn't knew too much about Hadoop and when I explained it to him he also found it not appealing at all, although he is spending quite some compute time on the groups cluster.
There exists a medium sized cluster at TU Berlin for the machine learning group. It consists of about 35 nodes, and hosts about 13TB of data for all kinds of research projects from the last ten or so years. But the cluster does not run on Hadoop, it uses Sun's gridengine, which is now maintained by Univa. There are historical reasons for that. Actually, the current infrastructure developed over a number of years. So here is the short-history of distributed computing at the lab:
Back in the early 2000s, people were still having desktop PCs under their desks. At the time, people were doing most of their work on their own computer, although I think disk space was already shared over NFS (probably mainly for backup reasons). As people required more computing power, people started to log into other computers (of course, after asking whether that was ok), in addition to several larger sized computers which were bought at the time.
That didn't go well for a long time. First of all, manually finding computers with resources to spare was pretty cumbersome, and oftentimes, your computer would become very noisy although you weren't doing any work yourself. So the next step was to buy some rack servers, and put them into a server room, still with the same centralized filesystem shared over NFS.
The next step was to keep people from logging in to individual computers. Instead, gridengine was installed, which lets you submit jobs in the form of shell scripts to execute on the cluster when there were free resources. In a way, gridengine is like YARN, but restricted to shell scripts and interactive shells. It has some more advanced capabilities, but people mostly submit it to run their programs somewhere in the cluster.
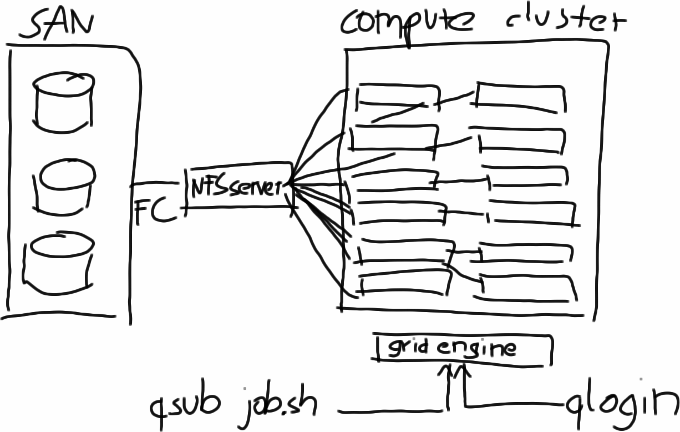 Compute cluster for machine learning research.
Compute cluster for machine learning research.
Things have evolved a bit by now, for example, the NFS is now connected to a SAN over fibre channel, and there exist different slots for interactive and batch jobs, but the structure is still the same, and it works. People use it for matlab, native code, python, and many other things.
I think the main reason that this system still works is that the jobs which are run here are mostly compute intensive and no so much data intensive. Mostly the system is used to run large batches of model comparison, testing many different variants on essentially the same data set.
Most jobs follow the same principle: They initially load the data into memory (usually not more than a few hundred MB) and then compute for minutes to hours. In the end, the resulting model and some performance numbers are written to disk. Usually, the methods are pretty complex (this is ML research, after all). Contrast this with "typical" Big Data settings where you have terabytes of data and run comparatively simple analysis methods or search on them.
The good message here is that scalable computing in the way it's mostly required today is not that complicated. So this is less about MPI and hordes of compute workers, but more about support for managing long running computation tasks, dealing with issues of job dependency, snapshotting for failures, and so on.
Big Data to Complex Methods?
The way I see it, Big Data has so far been driven mostly by the requirement to deal with huge amount of data in a scalable fashion, while the methods were usually pretty simple (well, at least in terms to what is considered simple in machine learning research).
But eventually, more complex methods will also become relevant, such that scalable large scale computations will become more important, and possible even a combination of both. There already exists a large body of work for large scale computation, for example from people running large scale numerical simulation in physics or meterology, but less so from database people.
On the other hand, there is lots of potential for machine learners to open up new possibilities to deal with vasts amount of data in an interactive fashion, something which is just plain impossible with a system like gridengine.
As these two fields converge, work has to be done to provide the right set of mechanisms and abstractions. Right now I still think there is a considerable gap which we need to close over the next few years.
React to this post
Comments (4)
The biggest difference seems between the world of numerical analysis and ML/big data from my point of view seems to be that a lot of big data frameworks want to archive a high level of generality whereas a lot of high performance algorithms are extremely specialized and only serve a very specific purpose - and (thinking of FEM/FDM for pdes), the data involved is more static and has a rather regular generation process.
Yeah, high performance computing for solving linear differential equations and other kind of physically motivated simulation has a high degree of internal structure which is exploited. I wonder what amount of generalization has been attempted in that area at all. No offense, but I think the people writing these codes were mostly physicists without proper training in software engineering, so the push to "frameworkize" was nowhere as strong as it is nowadays in the Big Data world.
There is a big divide between the Big Data (aka Hadoop) community and the machine learning community because they are independent. Machine learning does not need Hadoop. The Hadoop vendors need machine learning to work with Hadoop as that is where the real value is for them.
I agree that (academic) ML can safely ignore Hadoop for most of it's areas. Even when it comes to applications (e.g. computer vision), data comes from all kinds of proprietary systems which have existed long before the advent of Hadoop.
Still, I don't believe ML should ignore Hadoop because there is no way around it when you start dealing with data incompanies, and by gaining practical relevance, also the academic side of ML can benefit.