
Parts But No Car
One question which pops up again and again when I talk about streamdrill is whether that cannot be done by X, where X is one of Hadoop, Spark, Go, or some other piece of Big Data infrastructure.
Of course, the reason why I find it hard to respond that question is that the engineer in my is tempted to say "in principle, yes" which sort of questions why I put all that work to rebuild something which apparently already exists. But the truth is that there's a huge gap between "in principle" and "in reality", and I'd like to spell this difference out in this post.
The bottom line is that all those pieces of Big Data infrastructure which exists today provide you with a lot of pretty impressive functionality, distributed storage, scalable computing, resilience, and so on, but not in a way which solves your data analysis problems out of the box. The analogy I like is that Big Data is a lot like providing you with an engine, a transmission, some tires, a gearbox, and so on, but no car.
So let us consider an example where you have some clickstream and you want to extract some information about your users. Think, for example, recommendation, or churn prediction. So what steps are actually involved in putting together such a system?
First comes the hardware, either on the cloud or by buying or finding some spare machines, and then setting up the basic infrastructure. Nowadays, this would mean installing Linux, HDFS, the distributed filesystem of Hadoop, and YARN, the resource manager which allows you to run different kind of compute jobs on the cluster. Especially when you go for the raw Open Source version of Hadoop, this step requires a lot of manual configuration, and unless you already did this a few times, this might take a while to get to work.
Then, you need to take in the data in some way, for example, by something like Apache Kafka, which is essentially a mixture of a distributed log storage and an event transport plattform.
Next, you need to process the data, which could either be done by a system like Apache Storm, a stream processing framework which lets you distribute computing once you have it broken down to pieces of computation taking in an event at a time. Or you use Apache Spark which let's you describe computation on a higher level with something like a functional collection API and can also be fed a stream of data.
Unfortunately, this still does nothing useful out of the box. Both Storm and Spark are just frameworks for distributed computing, meaning that they allow you to scale computation, but you need to tell them what you want to compute. So you first need to figure out what to do with your data and this involves looking at data, identifying the kind of statistical analysis which is suited to solve your problem, and so on, and probably requires a skilled data scientist to spend one to two month working on the data. There are projects like mllib which provide more advanced analytics, but again these projects don't provide full solutions to application problems but are tools for a data scientist to work with (And they are still somewhat early stage IMHO.)
Still, there's more work to do. One thing people are often unaware of is that Storm and Spark have no storage layer. This means that they both perform computation, but to get to the result of the computation, you have to store it somewhere and have some means to query it. This means usually to store the result in a database, something like redis, if you want the speed of a memory based data storage, or in some other way.
So by now we have taken care of how to get the data in, what to do with it and how, and how to store the result such that we can query it while the computation is going on. Conservatively talking, we're already down six man months, probably less if you have done it before and/or are lucky. Finally, you also need to have some way to visualize the results, or if your main access is via an API, to monitor what the system is doing. For this, more coding is required, to create a web backend with graphs written in d3.js in JavaScript.
The resulting system probably looks a bit like this.
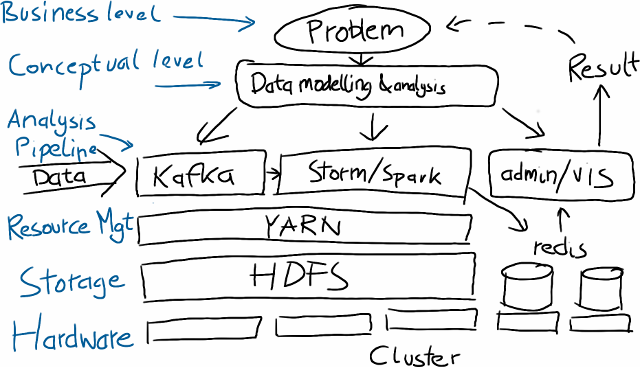
Lots of moving parts which need to be deployed and maintained. Contrast this with an integrated solution. To me this is difference between a bunch of parts and a car.
React to this post
Comments (5)
Traditional IT software systems are delivered as integrated usually from a single vendor. The pros and cons but with the movement towards cloud, the pros win. These software systems started small and over decades have grown into industrial-strength integrated systems.
There is a rush by the Big Data vendors to build monolithic stacks from various open source projects. The idea might make sense but there are many problems with this approach: this is a new area (and era) and no one yet knows what are the most efficient solutions; integrating disparate open source software packages is a disaster waiting to happen.
Couldn't agree more with your analysis.
"integrating disparate open source software packages is a disaster waiting to happen" - why is this? It all depends on the integration.
IMO it's way better than integrating disparate commercial solutions - which is something an enterprise can never avoid - there's no one single vendor which sells and supports all the perfect solutions for all of one enterprise's problems.
I agree that integration is not per se bad. I think the danger here comes from the fact that we are operating in a pretty complex space which is also only barely understood in its entirety. The probability that were buildings layers of abstractions which will later prove to work against what we need to do with this technology is high.
The other problem I see is whenever someone starts to put together something useful, there seems to be an overwhelming temptation to go commercial. Which is probably even well founded, because you are creating actual value.
However, from an open source point of view this is regrettable, because the pure OSS part of the software stays pretty complicated and incomplete in a way. To me, it seems that is exactly what is happening right now in the Big Data space.
Nice analysis. From a business perspective; what's missing is standardisation. I looks like every solution is taylor made. Would it be possible to script building the whole infrastructure in one click (with some parameters)? In the end it comes down to input (streaming) data , do the algorithmic thingy, get output (and eventually store it).
So, don't take the functional problem as starting point (however tempting that is), but focus on the problem how to solve problems with data analytics and do it in a standarised manner. This would drive down the cost, shortens the time line and would have a longer life cycle.
How can we analyse the different needs when analizing data? Put that in a model and facilitate that.
Google Cloud Dataflow is doing away with a lot of the complexity of managing runners, batch and streaming, getting a fully managed ETL service in the cloud https://cloud.google.com/da...