Why you should listen to your supervisor
The other day I was walking with my two children to an appointment we had on the playground. It wasn’t far away, probably 15 minutes of walk, but for some reason my kids were very slow. I kept telling them “C’mon, it’s just down this street, then going left and down another street and we’re there.” Still, they were very slow, going forward reluctantly, looking at the houses at both sides of the street.
Then it dawned on me: they had no idea where we’re going. I perfectly knew the route and to me, it was just a question of going there, but to them, it just looked like we were trotting down some boring road in the middle of the city, and they we’re wondering “why?”
I think the situation is similar if you’re a starting graduate student set out to spend the next X years of your life to get a Ph.D. It’s a pretty big project, probably the biggest endeavour you’ve embarked on so far. Then there are other subprojects like developing new methods, running experiments, writing papers, giving talks, etc. Afterwards, as a PostDoc, things are similar, writing grant proposals, getting funding, getting tenure, organizing a workshop, and so on. All of these projects involve many small steps and take a lot of time, from weeks to months, or even years.
It’s not even restricted to academia. If you think abou it life is full of those larger projects, and while you can intellectually grasp what lies ahead of you, this is much different from knowing the road because you’ve been there before. And that’s something your supervisor can provide to you, basically telling you that he knows the way and you should keep on walking and you’ll eventually get there.
Coffee Talk: Twitter Should Have Monetized Their API
This morning over coffee, Leo (a.k.a. thinkberg) and I discussed this post on the TwentyPeople blog on their problems with the Twitter API.
The story is that they started fruji, some kind of Twitter analytics project, as a side project, but it has since become so successful that they’re running into issues with Twitter’s API limits. As you probably know, Twitter only allows a certain number of requests to their API per hour. For Fruji, they have to get the list of followers for a user from Twitter. The biggest problem is that request often time out after 5 seconds, but still cost you one API call. They’ve build all kinds of workarounds, like backing off (requesting 50, 25, 10 followers, and so on, until they get a result, and then ramping up the queries, until the next timeout), but it is still a huge nuisance. For users which have hundreds of thousands of followers, getting all followers for the analysis takes a long time, even days or weeks. The problem is that Twitter is not doing anything about this issue.
This reminds me a lot of when we were using the search API to look for retweets for our twimpact analysis. That was back before the streaming API existed. We were periodically searching for the latest tweets containing “RT”, and then paging through the results. Every now and then we would hit a server which was apparently down and get a time-out, or even a response which said there were no results. Whenever that happened, we would also start to perform all kinds of workarounds, back-offs, and so on. But this often took so long that on the next round, we’d have to step through even more pages, resulting in potentially more errors, and so on.
Obviously, Twitter is not really doing a great service to all those companies and startups who try to build services around Twitter, and they probably also don’t have much incentive, because they’re making no money of the API access. They’ve started to sell their streams through gnip, but both Leo and I agree that the offerings are too big and just insanely expensive. They don’t seem to have the current numbers on the website, but half the Twitter stream costs a few hundred thousand dollars per year. Even Google eventually decided that this is just not worth it.
What they should have done is to provide a way to monetize the standard API with moderate rates. How about you get 100 API requests per hour for free, and the next 1000 for 5$ a month? That would be some model which gave startups a model to work with.
We suspect that there are two reasons why Twitter didn’t followed that path: They’re afraid that people will just steal their data to clone another social network, and they couldn’t sell that model to their investors. Investors probably love monetizing through ads. Google’s build their whole company on ads, so let’s do ads!
But I think they’re wrong. As Leo notices, once you’re in an actual business relationship with someone (and not simply someone clicking the “Yeah, I’ve read the ToS” button), you should be in a better position to sue them if they really use the data in some way which you don’t like.
In any case, I think the case for Twitter’s lost. App.net anyone?
Pheed, Tent.io, and the Future of Social Networks
Pheed made the news lately because they managed to get a large number of celebs to sign up for their service. Featurewise it’s somewhere between Facebook and Twitter, but the main difference is that you can charge people a monthly fee to follow you, or even for individual posts (called “pheeds”. It’s doesn’t stop there, comments on posts are called “pheedback”).
Now if you’ve read my social media wishlist you might now that I’m a fan of pay-per-view monetization, or at least I think that eventually people will be ready for the content or the audience reach they get on a social network site. If you have a gazillion followers and can bring down any moderately sized web site just by mentioning a link, why shouldn’t you pay for that awesome power?
However, and this is where Pheed is doing it wrong, I don’t think that people will be willing to pay a lot of money for that. On Pheed you can charge people from $1.99 to $34.99 a month to follow your feed, or anything from $1.99 to $34.99 for an individual post (say a new MP3 or a video). Sorry, $2.99 a month just to follow Chris Brown’s life. How does that scale? Do you really think people are willing to pay about thirty bucks to follow their favorite ten celebrities? I don’t think so. Hopefully, Pheed will have different offerings, like a flatrate for $10 a months or something more reasonable, otherwise I don’t believe they’ll be making a lot of money.
Interestingly, Pheed came with rather tight Twitter integration. You could sign in using Twitter, or even tweet from the Pheed website. Unsurprisingly, Twitter cut of Pheed’s API access rather quickly. Twitter’s position is pretty clear, they won’t have it that another social network feeds of the user’s connection on Twitter.
While this is certainly understandable, I also think that Twitter is missing a big opportunity for making some serious money, which brings me to another favorite topic about the current state of the art with social networks.
Depending on who you ask, people have different opinions on what is the biggest problem in social media networks. Some complain that companies are taking all their data and selling it, that you don’t have proper control about your data. But I personally think that the biggest problem is that it is almost impossible to try out something new.
The problem with designing new social media features is that you need a sizeable set of users to see whether ideas really work. But as it is right now, this means that in order to build something new, you have to kickstart your own social networks, and honestly, I think the number of social networks you can be on is a pretty small number.
People who think that control is the biggest problem tend to say that decentralization is the way to go, and efforts like PubSubHubBub, diaspora, or tent.io go in that direction, by essentially proposing protocols and building example servers such that we get a decentralized network of servers where everyone can control his own data.
Then there is also App.net who says that the main problem currently is that social media sites have to make money by selling your data because they offer the service for free. On App.net you consequently have to pay about $5 per month to join, but the system itself is again centralized.
I’d personally like to see a solution which is somewhere inbetween. You can have big sites which host millions of users, and also individual smaller servers if you want, but all these sites form one big social media space. It would be able to subscribe to a user which is on any site, irrespective of whether he is on your own site or not.
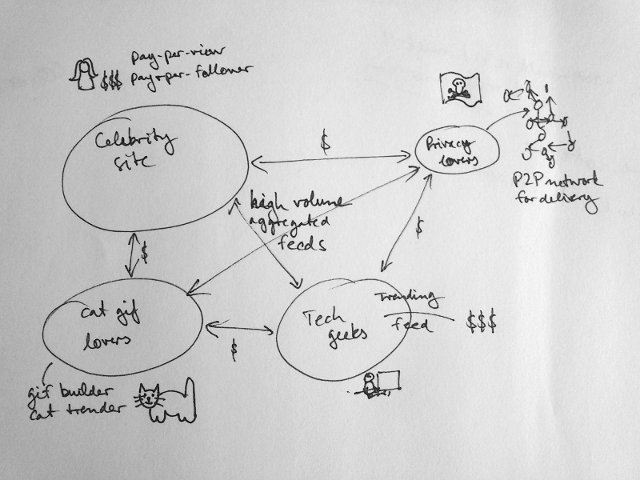
For that, we need a more high-level protocol which connects the different sites and lets them exchange all the updates they have subscribers for in an aggregated fashion.
This approach has a number of advantages IMHO:
-
The approach is more scalable than a fully decentralized approach. Instead of delivering each message individually to all your subscribers, you only deliver them to the sites which has subscribers which then internally routes your messages using whatever technology it pleases.
-
Sites can hook into the existing infrastructure so users don’t have to completely switch with all your friends to a new social media site, since you can still see the updates from the other sites. Whether you want to switch becomes more dependent on certain features, the easy to share media you’re interested in, etc.
-
Sites can start charging one another for subscribing to users. This also gives an incentive to make your site not suck and attract users which have a lot of followers. If you manage to get Lady Gaga on your site, you will be able to cash in on her content alone (and probably also charge her for her insane number of followers).
-
Some degree of centralization also means that you can do trend analysis or impact analysis, which might be even more useful if you focus on a specific user set. Say your site focusses on tech users, then their trends might even be interesting for companies that they would like to buy this information. For celebrities, getting deep analytics on their impact might be so valuable that they are willing to pay a premium for getting real-time analytics, and so on.
-
Internally, sites are free to try out different sets of features, technologies, and monetarization schemes. You can build a site to attract celebrities, news outlets, or brands, or tech geeks, teens, or privacy die-hards. You can build your own monolithic server farm or rely on P2P to deliver the posts within your framework. You can build services which are free (but cannot access paid content), or you can put a price tag on everything. You can let users pay-per-view or pay-per-follower. The list goes on and on… .
I think people have begun to see that social media sites have some value to users and companies, but to get to the next level, we’d need a bit of infrastructure to create a veritable industry.