Book Review: 'Debt: the first 5000 years' by David Graeber
Just finished reading “Debt: The first 5000 years” by David Graeber. A very interesting book for anyone interesting in getting some perspective on the financial crisis and generally our modern world of economics. The book does this not by discussing the current crisis, but by taking a historical perspective on debt.
Being an anthropologist (and apparently one of the inspirations behind the occupy movement, something I was totally unaware of until I checked him on the Net to look for other books written by him), David Graeber takes the reader on a tour de force through the last 5000 years of human history, starting with the ancient civilizations in Mesopotamia, covering ancient Greece, the Roman empire, the Middle Ages in Europe, Arabia, and China, finally arriving in the industrial revolution and the present time.
The first thing the book does is to discuss the usual myth that money was invented to make barter and exchange of goods easier. You’ve probably all heard about this at some point of your life. While in a barter economy, people (hypothetically speaking) would have to have an exact match of needs in order to do an exchange, money made this much easier. So instead of Bob having to find someone to give him meat in exchange for leather, he could just pay someone money, and everything is fine.
The point is that since Adam Smith, the founding father of economics, has told this story, anthropologists failed to find a single community of humans where money has been invented in this way. Even more interestingly, the problem of an exact match of needs simply does not occur. In reality, people are usually in some form of relationship, say as members of the same village, and what invariably happens throughout human history is that people work with some form of keeping track of who owns what to whom. So if Bob needs meat, he simply gets the meat from Frank, but he will then owe Bob some equivalent of meat. Often goods are roughly divided into a hierarchy of objects to keep track of who owes what to whom, and that seems to work quite fine most of the time.
The first conclusion of the book is therefore that debt predates money, contrary to what we normally believes.
The book then explores how debt and money have developed over the ages. I found it a very interesting read. As it turns out, history has seen cycles of going from very money intensive times (in the sense that people were using coins) to times of virtual money and credit. For example, at the beginning of the middle ages, coins practically disappeared because it was used to pay for chinese luxuray goods or hoarded in churches and temples. People kept on counting their debts in Roman currencies, but otherwise people reverted back to the book-keeping of who owes what, balancing the debts every few months.
Finally, the book also argues that the usual economic point of view that everything is an exchange and humans always just try to maximize their personal gain is plainly wrong. Instead, there are at least two other ways in which people usually interact, one being what Graeber calls “communism”, that is, people more or less freely helping out each other as best as they can, and the other being “hierarchy”, as in the middle ages.
Concerning our current situation, the book also doesn’t have any final answers, but Graeber points out that we’re at the beginning of a new age of virtual money, which started when the US abandond the gold standard in 1971, and the question is whether we can learn from our past and find some new answers. One of the outspoken goals of the book is to free us from common misconceptions on the origin of money and the meaning of debt, and I think the book does a very good job at this.
Levels of Abstractions in Big Data
Recently we’ve spoken to a number of people to find out how our real-time stuff could be of use to them. Those were all very interesting conversions, but sometimes it happened that it became more about how to fit our approach into an existing infrastructure than discussing the merits of our approach for a given application.
I think it’s not uncommon if discussing software that the question of how to fit something on an existing framework is important, but for two reasons I think that’s even more the case with Big Data.
In the end, it’s a question about what kind of abstraction a piece of software provides. You might be familiar with the idea that the language used to describe something influences the way you think about a problem. That is certainly even more true in programming where the way a certain piece of software models some part of reality is not just theory, but puts hard constraints on what you can do. Some things are easier to express than others, some things might require workarounds, while other things might be downright impossible.
While this is certainly true of any type of software, I think the consequences are even more severe in the area of Big Data because abstractions there are often quite new and potentially imperfect and because there is considerably more technical lock-in into a given solution.
Many of the tools like Hadoop or NoSQL data bases are quite new and are still exploring concepts and ways to describe operations well. It’s not like the interface has been honed and polished for years to converge to a sweet spot. For example, secondary indices have been missing from Cassandra for quite some time. Likewise, whether features are added or not is more driven by whether it’s technically feasible than whether it’d make sense or not. But this often means that you are forced to model your problems in ways which might be inflexible and not suited to the problem at hand. (Of course, this is not special to Big Data. Implementing neural networks on a SQL database might feasible, but is probably also not the most practical way to do it.)
In particular for Big Data, exchanging one solution for another can be quite hard. You’ve already invested into your infrastructure, all your data is in there, your monitoring infrastructure is tailored to your compute cluster, and so on. And few have the resources to run two different clusters in parallel. Also, since the field is quite new and there is little standardization, switching between frameworks is impossible without rewriting core functionalities.
You might ask why you should care. After all, the technical properties of the software you are using are a reality you have to deal with. But I think being too focused on how your current solution views the world might be a problem when you try to explore other approaches to do interesting stuff with your data, and ways to scale your computations.
So what can we do about this? Not much, but we can try to keep in mind that there are different ways to think about algorithms and represent them. Some classical examples:
-
“Normal” theoretical computer science is often pretty low-level with objects (more in the sense of C structs), arrays, and pointers. You can also throw standard data structures like trees, hash maps, linked list, etc. in there. Not all of these might be easily mapped to your favorite Big Data tool, but this is a very flexible way to think about algorithms with state.
-
Machine learning encodes a lot of stuff in either linear algebra or probability theory. Matrices and vectors are pretty boring data structures, but linear algebra gives you a very geometric way of thinking about things. Probability theory again comes with its own ideas and concepts, and many of the operations can be expressed as matrix operations (at least when the underlying set of events is finite).
-
Stream processing in the sense of worker threads which pass messages around is also a common way to think about algorithms. Stream processing frameworks and actor based concurrency allow you to express such concepts naturally.
-
Recursion is also a standard way to think about algorithms which again might be hard to map into a MapReduce framework.
In the end, I think you should choose the abstraction which let’s you express the algorithm in the simplest way to think about it, instead of letting your existing installation tell you how to do it. A nice thing about software is that you can actually map between abstractions by writing a bit of interface code. It might not always be painless and certain operations might be more expensive than you’d expect them to be, but what you gain is flexibility in thinking about your algorithms.
Why you don't want real-time analytics to be exact
In case you haven’t noticed yet, real-time is pretty big topic in big data right now. The Wikipedia article on big data goes as far as saying that
"Real or near-real time information delivery is one of the defining characteristics of big data analytics."
There article like this one by the Australian Sydney Morning Herald naming real-time as one of the top 6 issues in big data. At this year’s BerlinBuzzword conference there were at least four talks talking about real-time.
Now if you look at what people are mostly doing, you see that they are massively scaling out MapReduce or stream processing approaches (as in this blog post on the DataSift infrastructure I’ve already mentioned before), and/or moving to in-memory (for example GridGain who also seem to be burning through quite a marketing budget right now) to get faster.
Now as I have stated before, I don’t believe that scaling can be the ultimate answer, but we also need better algorithms.
At TWIMPACT, we’ve explored that approach using so-called heavy hitter algorithms from the area of stream mining and found these extremely valuable. Probably their most important property is that they allow you to trade in exactness for speed. This allows you to get started very quickly without having to invest in a data center first just to match the volume of events you have (or do things like deliberately down-sampling which again introduces all kinds of approximation errors).
However, whenever we’re talking to people about our approach this is always a hard point to sell. Typical questions were “How can we guarantee that the approximation error is in check?” Or “Isn’t big data about having all the data and being able to process it all?”
So here is my top 4 list of reasons why you don’t want exact real-time:
Reason 1: Results are changing all the time anyway
First of all, if you have high volume data streams, your statistics will constantly change. So even if you compute exact statistics, the moment you show the result, the true value will already have changed.
Reason 2: You can’t have real-time, exactness, and big data
Next, real-time big data is very expensive. As explained very well on slide 24 of this talk by Tom Wilkie, CTO of Acunu, there is something like a “real-time big data triangle of constraints”
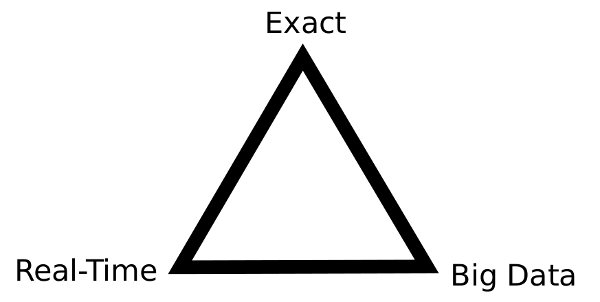
You can have only two: Real-time and Exactness (but no Big Data), Real-Time and Big Data (but no Exactness), or Big Data and Exactness (but not Real-Time). That is, unless you’re willing to pay a lot of money.
Reason 3: Exactness is not necessary
Unless you do billing, exact statistics seldom matter. Typical applications for real-time big data analysis like event processing for monitoring are about getting a quick picture of “what’s happening”. But that means you’re only interested in the top most active items in your stream. So it’s the ranking that counts and that won’t be affected by a small amount of exactness.
Of course, this also depends on the distribution of your data. The worst case for stream mining is data which is uniformly distributed (in the sense that all the events occur with equal probability). But for real world data, this is hardly ever the case. Instead, you have a few “hot” items and a long tail of mostly inactive items which is often of little interest to you.
Reason 4: You already have an exact batch processing system in place
Often, you already have a standard data warehouse which can give you exact numbers if you need them, but you start to get interested in a more real-time view. In that case it doesn’t really make sense to spend a fortune on an infrastructure to give you exact results in real-time just to get an idea of what’s happening.
Put differently, real-time analyses and standard batch-oriented analyses have quite different roles in your business. Batch-oriented number crunching is done once a month to do the accounting while real-time is used for monitoring. And for that you don’t need exact numbers as much as you do for accounting.