Slides for my LinuxTag talk on Cassandra
Last Friday, I gave a talk a the LinuxTag conference in Berlin (BTW, "Tag" means "Day" in German) on Cassandra. The goal was to give an introduction to Cassandra and also talk a bit about the experiences we've made with Cassandra at TWIMPACT.
I also got some interesting feedback. In particular, someone pointed out that we're having pretty atypically high write rates in our analysis application compared to normal web applications, also leading to more frequent compaction.
I probably should also add that we've recently moved away from Cassandra to a completely memory based approach. We felt that real-time demanded that you hold all your important data in memory and use disk only to store logs and other aggregated data.
I'm also not saying that Cassandra (or Postgres for the matter) is inherently slow or buggy, I think (as always) it's very much a matter of what kinds of requirements you have.
Tuning ATLAS for jblas
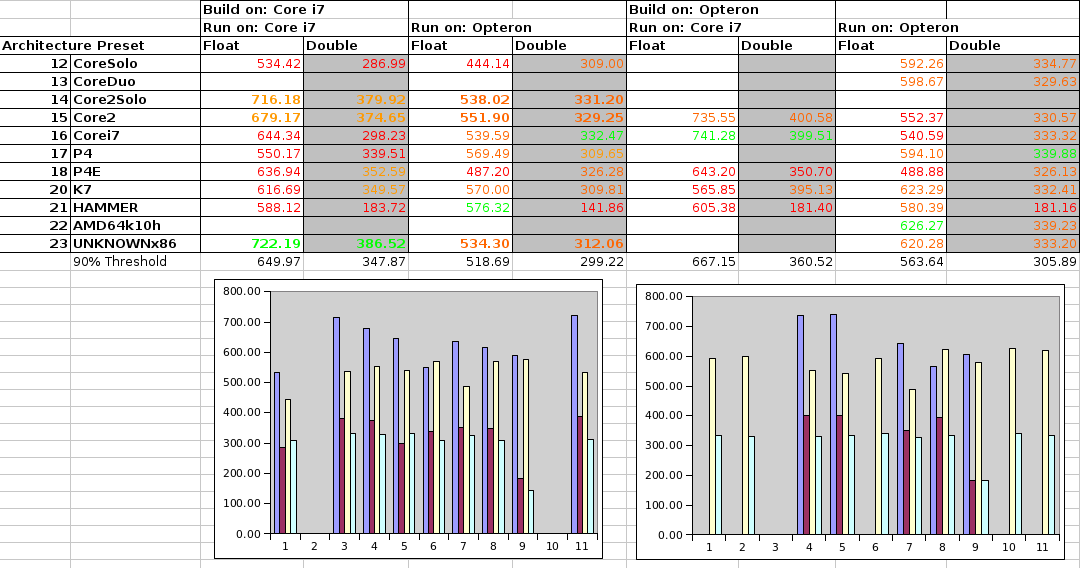
Finally I find some time to recompile the ATLAS libraries for jblas. As it has turned out, the libraries which shipped with jblas 1.2.0 were 30% to 50% slower than what shipped in earlier versions. This still made jblas faster than pure Java implementations, but there are still a lot of FLOPS missing.
To solve this problem once and for all, I did some exhaustive benchmarkings of compiling and running ATLAS on different platforms. I started with 64 bit Linux and the SSE3 settings. I used the following two processors:
- Intel Core i7 M 620 with 2.67 GHz, 4MB Cache
- AMD Opteron 2378 (quad core), 2.39 GHz, 512 KB Cache
Above are the results for compiling on the i7 or on the Opteron and running on the i7 or the Opteron processor. The numbers shown are relative MFLOPS for large matrix-matrix multiplications (100 would mean 1 floating point operation per clock cycle). The best setting is shown in green, those above 90% of that in orange, and those below in red. Numbers which are missing didn’t compile or run.
As you can see, it’s really not that easy to pick the best configuration. It’s not even the case that the architecture presets for the given platform produce the best results.
If you build on the Core i7, the presets Core2Solo, Core2, and UNKNOWNx86 lead to good performances both on the Core i7 and the Opteron. If you build on the Opteron, there is no preset which gives good results on both processors.
So I think I’ll settle on the Core2Solo which will give the following results:
- Core i7:
- single precision: 716.18% (best possible: 741.28%)
- double precision: 379.92% (best possible: 399.51%)
- Opteron
- single precision: 538.02% (best possible: 626.27%)
- double precision: 331.20% (best possible: 339.88%)
To really get the best possible performance, you’d need to use the best possible implementation, but that would mean to inflate the jar even more.
I’m note sure which road to take here. GotoBlas2 has recently been released under a BSD licence and also shows very promising results, which would further increase the number of shared libraries to put in the jar file.
Another option would be to have a central repository with all kinds of libraries, and then you would need to download and install the right one the first time you run jblas. Would that be too bad?
Getting Started in Scala
Often, when you search around for posts on Scala, you find pretty scary looking posts which discusses some rather advanced topic of the Scala type system or something similar, or just how functional Scala is by reimplementing ideas from Haskell in it.
On the other hand, I’ve been using Scala for more than a year now, and I find the whole experience very agreable, not because of the crazy stuff you can do in Scala (well, at least, not ONLY because of the crazy stuff), but because of the everyday improvements over Java Scala provides. For example:
- Type inference for variables. No need to be overly repetitive like
in
Map[String,String] table = new HashMap[String,String];. The default is that the variable is just the type of its initial value. - Declaring final variables with “val”. In Java, you can in principle tag variables as being constants by adding the “final” keyword, but in practice, I never see myself doing this because it is too much typing overhead. In Scala, I start with everything being a “val” and use “var” variables only if I really must.
- Functional data structures. By this I mostly mean data structures which provide methods like “map” or “filter”. Much easier than writing a whole bunch of for loops.
In any case, here is what’s necessary to get you started with Scala (assuming you already know enough Java and the infrastructure.)
Downloading Scala
Just download Scala, unpack and add the “bin” directory to your PATH.
Development Support
I’ve tried the following three IDEs.
- IntelliJ IDEA, Community Edition In my opinion, this is the best solution. Install the Scala plugin gives you a really good Scala support. The Community Edition also gives you sufficient support for Java, web development, etc.
- Netbeans with erlybird Scala plugin I’ve tried this for some time, no idea what the current status is. Last time I checked Scala support was quite good, but every once in a while, the parser had to be restarted.
- emacs. A special Scala edit mode is contained in the Scala destribution in “…/misc/scala-tool-support/emacs/”. Follow the install description in the README file in that directory.
Build Systems
You can go with either maven or sbt.
- Maven. Use the maven-scala-plugin which provides everything you need.
- simple-build-tool sbt is a command line tool which gives support to Maven-like dependency management. It also has a nice mode where it recompiles files whenever they change. This is really useful if you use an editor without code analysis to spot syntax errors.
Learning about Scala
- I can recommend two books, “Programming in Scala” and “Programming Scala”. I’ve reviewed both books earlier.
- The a huge list of tutorial, videos and articles on getting started with Scala.
- The scaladoc API for the Scala library.
Some more tips to get you started
I found that a great way to start playing around with ideas is to use the script mode of Scala. You can directly run files by typing “scala some-file.scala”. In Scala, you can put as many classes into a file as you want, so why not just do a quick sketch of your ideas in a single file.
For all those people coming from Java, here is a short list of things you should know:
- Types are essential for method arguments, and when you exit a function using “return.” Everything else is optional. (I’m simplyfing, of course.)
- There is no throws clause. (But there is an annotation for that if you really need to.)
- If you override a method, you have to say “override def”.
- Things you should check out: Pattern matching, “apply” method in the companion object, implicit conversions, Scala collections (in particular immutable collections.)
- For Scala 2.8.x, type “import scala.collection.JavaConversions._” to use methods like “map” and “foreach” on Java collections.
Speeding up Scala compilations
Unfortunately, the current implementation of the scala compiler takes very long to start up (a few seconds). To improve this, the scala distribution comes with a scala server called “fsc” which runs in the background, and you should definitely use it.
In Maven, the default to use fsc is controlled by the useFsc parameter of the scala:cc goal, but the default is true according to the documentation.
In IDEA, you control the setting through “Compiler > Scala > Use fsc (fast scalac)”.
Using fsc also has it quirks. Sometimes, when a lot of classes change or are renamed, it gets confused and needs to be restarted with “fsc -reset”. Especially on Linux, IDEA cannot compile if the fsc isn’t already running. You can vote up the bug, for the mean time, you need to periodically run a small compilation in order to keep fsc from shutting down.
Before I start to work, I start the following script
#!/bin/bash
fsc -shutdown
while true; do
scala $HOME/helloworld.scala
sleep 1500
donewith the file helloworld.scala being the one-liner
println("Did some random run of scala at %s.".format(new java.util.Date))or something similar.