Machine Learning: Beyond Prediction Accuracy
Okay, let’s start this year with something controversial. The other day I was meeting with some old friends I met at university and we were discussing about machine learning. They were a bit surprised when I disclosed that I became somewhat disillusioned with machine learning because I felt there was any resemblance of intelligence missing in even the most successful methods.
The point I tried to make was that the “mind” of machine learning methods is just like a calculator. If you take a method like the support vector machine (and in extension practically all kernel methods), you will see that the machine does in no way “understand” the data it is dealing with. Instead, millions of low-level features are cleverly combined linearly to achieve predictions which have remarkable accuracy.
On the contrary, if we human learn to predict something it seems (and I know that there is a risk with introspection when it comes to mental processes) that we also begin to understand the data, decompose it into parts and understand the relations between these parts. This allows us to reason about the parts, and also prepares us to transfer our knowledge to new tasks. Leaving prediction tasks aside, we can even just take in a whole set of data and understand its structure, and what it is.
I went on to explain that the same is even true of more complex, structured models like neural networks or graphical models. In neural networks, it is still unclear whether it really achieves some internal representation having semantic content (but see our NIPS paper where we try to understand better how representations change within a neural network). As for graphical models, the way I see it, they are very good at extracting a certain type of structure from the data, but this structure must be built into the structure of the network.
Actually, my complaint went further than this. Not only are even the most successful methods lacking any sign of real intelligence and understanding of the data, but the community as a whole also seems to be content to just keep following that part.
Almost every time I have tried to argue that we should think about methods which are able to autonomously “understand” the data they are working with, people say one of these two things:
-
Why would that get me better prediction accuracy?
-
The Airplane Analogy: Airplanes are also much different from birds with their stiff wings and engines. So why should learning machines be modeled after the human mind?
People seem to be very much focused on prediction accuracy. And while there are many applications where high prediction accuracy is exactly what you want to achieve, from a more scientific point of view, this represents an extremely reductionistic view of human intelligence and the human mind.
Concerning the second argument, people overlook the fact that while airplanes and birds are quite differently designed, they nevertheless are based on the same principles of aerodynamics. And as far as I see it, SVMs and the human mind are based on entirely different principles.
Learning Tasks Beyond Prediction Accuracy
At this points, my friends said something which made me think: If everyone is so focused on benchmarks, and benchmarks apparently do not require us to build machines which really understand the data, it is probably time to look for learning tasks which do.
I think this is a very good question. Part of the problem is of course that we have a very limited understanding of what the human mind actually does. Or put differently, being able to formally define what the problem is probably already more than half of the answer.
On the other hand, two problems come to mind which seem to be good candidates. Solutions exist, but they don’t really work well in all the cases, probably due to a lack of “real” intelligence: computer vision (mainly object recognition), and machine translation
If you look at current benchmark data sets in computer vision like the Pascal VOC challenges, you see that methods already achieve quite good predictions using a combination of biologically motivated features and “unintelligent” methods like SVMs. However, if you look closer, you also see that there are some categories which are inherently hard, and much more difficult to solve than other categories. If you look at the classification results, you see that you can detect airplanes with 88% average precision, but bottles only with 44%, or dining tables with 57%. I’d say that the reason is that you cannot just “learn” each possible representation of a dining table with respect to low-level features, but you need to develop a better “understanding” of the world as seen in two-dimensional images.
I don’t have similar numbers for machine translation, but taking Google translate as an example (at least I think it is safe to say that they are using the most extensive training set for their translations), then you see that results are often quite impressive, but only in the sense that you can still understand what the text is about by parsing the result, which is full of errors on every level, as a human.
These are two examples of problems which are potentially strong enough require truly “intelligent” algorithms. And I still have no idea what that might exactly mean, but it’s probably neither “symbolic” nor “connectionist” nor Bayesian, some mix of automatic feature generation and EM algorithm, probably.
Note that I didn’t include the Turing test. I think it is OK (and probably even preferable) if the task is defined in a formal way (and without refering back to humans for that matter).
In any case, I enjoyed talking to “outsiders” quite much. They are unaware of all the social implications of asking certain kinds of questions (What are the hot topics everyone is working on right now? Will this make the headlines at the next conference? What are senior researchers thinking about these matters), and every once in a while we should also step back and ask ourselves what the questions are we’re really interested in, independently of whether there is any support in the community for it or not.
Books in Pairs: Programming in Scala vs. Programming Scala
I’ve been using Scala for probably a year now, and I’m actually quite impressed with the language. In most languages, you sooner or later come across something which is just plainly broken. Everyone knows it is broken, but clearly, there is no way to do anything about it, so everyone uses one work-around or another. Surprisingly, although I’ve come close, all in all the language is really very well thought out and quite powerful and fun to use.
For those of you who don’t know: Scala is a language for the JVM (and apparently also for the .NET framework, although I haven’t tried that out yet). This means that the compiler produces normal Java byte code and therefore has access to the many existing Java libraries and projects. Other such languages are Clojure, JRuby, or Groovy. Scala is a statically typed language which sees itself as a synthesis of object oriented and functional programming. I’ve already sung the song of praise for Scala in another post.
Luckily, there are several good books available, of which I’ve read two this year:
- Programming in Scala by Odersky, Spoon, and Venners (the guys who wrote Scala), artima.
- Programming Scala by Wampler and Payne (who did some Scala programming for Twitter), O’Reilly.
Since the titles are so similar, I’ll just stick with the publishers for the rest of the review.
So which of the books should you buy to learn Scala? I’d say both.
The artima book is probably a bit more pure. It covers Scala in all its glory, focusing on different language features in every chapter. Martin Odersky is the creator of Scala, so his understanding of the language is thorough. I would probably go to the artima book first if I wanted to know everything about some obscure language feature.
On the other hand, while there is an extensive number of examples, they feel somewhat academic. Of course, many programming language books are like this, but while the authors make some effort to find relevant problems, I was often left with the feeling that something was missing. As we all know, development in the Java environment has it’s ugly places with all those imports, Maven project files, and so on. So if they build a spreadsheet with a few hundred lines of code (they do!), I couldn’t quite believe it.
This is where the O’Reilly book comes in. What I really liked about the book is how it is written for people who already have some professional background and doesn’t spare you all the nasty details. In the end, the book covers roughly the same scope as the artima book, but at the same time also gives convincing example why and how you would use certain features. I would probably go to the O’Reilly book first if I wanted to know how different language features interact and can be put to good use in practice.
So in summary, I can heartily recommend both. Depending on how you usually approach new programming languages you can pick one of the two books to start and later add the other book to fill in the missing pieces.
The O’Reilly book also covered new features in Scala 2.8, which the artima book didn’t, but I just learned that the second edition of the artima book is completed and will be available in printed form in January 2011.
Finally, the O’Reilly book can also be found online on the books homepage.
Cassandra Garbage Collection Tuning
Last week, I discussed our experiences with configuring Cassandra. As some of the commenters pointed out, my conclusions about the garbage collection were not fully accurate. I did some more experiments with different kinds of GC settings, which I will discuss in this post. On the bottom line, it is not that hard to get Cassandra run in a stable manner, but you still need a lot more heap space than a back-of-the-envelope computation based on the Memtable sizes would suggest.
This post got a bit technical and long as well. The take-home message is that I obtained a much more stable GC behavior with setting the threshold at which the garbage collections of the old generation occurred to a lower value, leaving a bit more headroom. With that, I managed to run Cassandra in a stable manner with 8GB of heap space.
Short overview of Java garbage collection
(For the full details, see the article Memory Management in the Java HotSpot® Virtual Machine)
Java (or more specifically the HotSpot JVM) organizes this heap into two generations, the “young” and the “old” generation. The young generation furthermore has a “survivor” section where objects which survive the first garbage collection are stored. As objects survive several generations, they eventually migrate to the old generation.
The JVM runs two different kinds of garbage collections on the two generations. More frequent ones on the young generation, and less frequent ones on the older generations. The JVM implements different strategies:
-
Single threaded stop-the-world garbage collection Both garbage collections stop all running threads and run on a single-thread.
-
Parallel stop-the-world garbage collection Again a stop-the-world garbage collection, but the collection itself is running in a multi-threaded fashion to speed up the collection.
-
Concurrent mark-and-sweep (CMS) phase In this version (what is also used by Cassandra when you use the default setting), the garbage collection for the old generation takes place in a concurrent manner (that is, running truly in parallel to your program), except for a short start and end phase. This type of garbage collection also comes in an “incremental” flavor which slices up the concurrent phase to lessen the overall load on the computer.
There are many different “-XX” flags to tune the garbage collection. For example, you can control the size of the young generation, the size of the survivor space, when objects will be promoted to the old generation, when the CMS is triggered, and so on. I’ll try to give an overview of the most important options in the following section.
Tuning GC for Cassandra
GC parameters are contained in the bin/cassandra.in.sh file in the
JAVA_OPTS variable. One tool to monitor is the jconsole program I
already mentioned which comes with the standard JDK in the bin
directory. With it, you can also look at the different generations
(“young eden”, “young survivor”, and “old”) separately. Note however,
that jconsole does not seem to count CMS GCs correctly (counter is
always 0). It is better to enable GC logging with
JAVA_OPTS=" \
...
-XX:+PrintGCTimeStamps \
-XX:+PrintGCDetails \
-Xloggc:<file to log gc outputs to>"As I said the previous post the most important part is to give yourself sufficient heap space. Still, there are other options you might wish to tweak.
Control when CMS kicks in
I’ve noticed that often a CMS GC would only start after the heap is almost fully populated. Since the CMS process takes some time to finish, the problem is that the JVM runs out of space before that. You can set the percentage of used old generation space which triggers the CMS with the options
-
-XX:CMSInitiatingOccupancyFraction=percentage Controls the percentage of the old generation when the CMS is triggered.
-
-XX:+UseCMSInitiatingOccupancyOnly ensures that the percentage is kept fixed.
Without these options, the JVM tries to estimate the optimal percentage itself, which sometimes leads to too late triggering of the CMS cycle.
Incremental CMS
I found recommended options for incremental CMS in this article:
-XX:+UseConcMarkSweepGC \
-XX:+CMSIncrementalMode \
-XX:+CMSIncrementalPacing \
-XX:CMSIncrementalDutyCycleMin=0 \
-XX:+CMSIncrementalDutyCycle=10With these options, the mark and sweep will run in small slices leading to lower CPU load. Interestingly, incremental CMS also leads to somewhat different heap behaviors (see below).
Tuning young generation size and migration.
From this very good tutorial on GC training is the following quote: “You should try to maximize the number of objects reclaimed in the young generation. This is probably the most important piece of advice when sizing a heap and/or tuning the young generation.”
There are basically two ways to control the amount of re-used objects: The size of the young generation and the way when they get promoted to the old generation.
Here are the main options for tuning the size of the young generation.
-
-XX:NewSize=size Initial size of the young generation. (You may use suffixes such as m, g, e.g. -XX:NewSize=32m)
-
-XX:NewMaxSize=size Maximal size of the young generation.
-
-Xmnsize sets size of the young generation fixed to given size. (For example, -Xmn32m)
-
-XX:NewRatio=n sets the ratio of young generation to old generation to 1:n (for example n = 3 means you’ll have 25% new generation and 75% old generation.
The size of the survivor space and the migration is controlled by the following options:
-
-XX:SurvivorRatio=n sets the ratio of “young eden” to “young survivors” to 1:n.
-
-XX:MaxTenuringThreshold=age controls at what age (that is, number of survived garbage collections) objects migrate to the old generation.
There still more options, check out the talk above for more information.
Some experiments
In order to test the different settings, I ran the following benchmark: I ran a somewhat memory constrained Cassandra instance with only 1MB per Memtable, and 400MB initial and maximal heap. Then, I analyzed about 700,000 tweets. Such a run took about 1 hour on my laptop (2GB RAM, Intel Core2 @ 2GHz, 500GB Seagate Momentus 7200.4 hard drive). I did some light coding during the tests.
I compared the following settings:
- cassandra-default uses the GC parameters which come with cassandra 0.6.3. The options are basically as follows, enabling concurrent mark and sweep, setting a somewhat low survivor ratio, and faster migration since objects are tenured at age one.
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=1
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSParallelRemarkEnabled-
jvm-default no special GC tuning. This results in parallel stop-the-world GC both for the young and old generation. I kept the settings for survivor ratio and tenuring threshold for better comparability.
-
cms-threshold same as above, but with a fixed CMS initiating occupancy of 80 per cent.
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=1
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=80
-XX:+UseCMSInitiatingOccupancyOnly- cms-incremental same as above, but with the incremental settings from above.
-XX:+UseConcMarkSweepGC
-XX:ParallelCMSThreads=1
-XX:+CMSIncrementalMode
-XX:+CMSIncrementalPacing
-XX:CMSIncrementalDutyCycleMin=0
-XX:CMSIncrementalDutyCycle=10The following plot shows the size of the used old generation heap, both as a smoothed mean (running mean over 5 Minutes), and the cumulative maximum. Note that the raw data is much more jagged, basically covering the space between the line cms-incremental and the respective maximum.
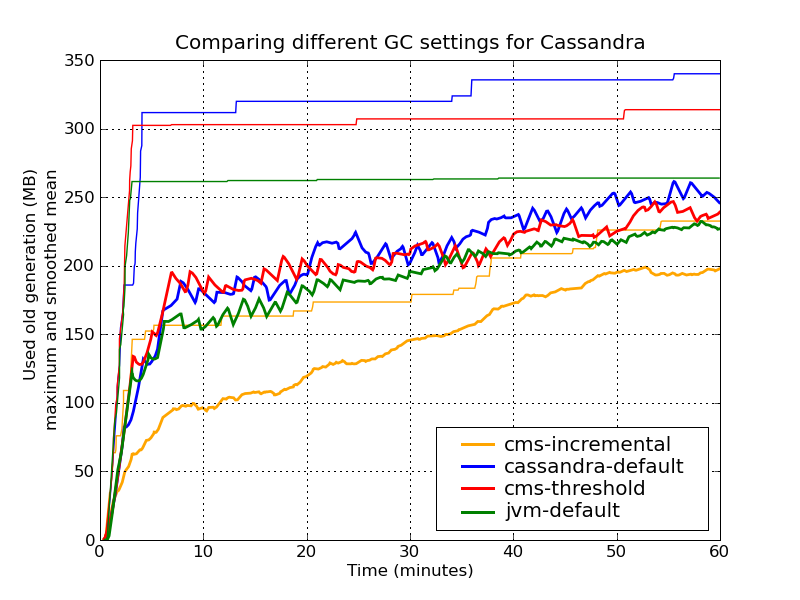
In principle, all settings worked quite well, getting a bit of stress from the garbage collector as the heap ran full. This sometimes resulted in time outs as requests took a bit too long.
From this plot we can conclude that
-
The mean heap usage is quite similar.
-
The default JVM settings actually perform quite well, however with stop-the-world full garbage collections.
-
The default cassandra settings has the highest peak heap usage. The problem with this is that it raises the possibility that during the CMS cycle, a collection of the young generation runs out of memory to migrate objects to the old generation (a so-called concurrent mode failure), leading to stop-the-world full garbage collection. However, with a slightly lower setting of the CMS threshold, we get a bit more headroom, and more stable overall performance.
-
Interestingly, the incremental CMS leads to much lower heap usage. However, note that it adds additional constant CPU load due to the continual garbage collections.
Conclusion
In summary, a bit of garbage collection tuning can help to make Cassandra run in a stable manner. In particular, you should set the CMS thresholds a bit lower, and probably also experiment with incremental CMS if you have enough cores. Setting the CMS threshold to 75%, I got Cassandra to run well in 8GB without any GC induced glitches, which is a big progress from the previous post.
Credits: Cassandra monitoring with JRuby and jmx4r, plotting with matplotlib.
Update
Based on Oleg Anastasyev suggestion, I re-ran the experiments and also logged the CPU usage. I ran the new experiments on one of our 8 core cluster computers which had no other workload, because my Laptop has only two cores.
Since the server is a 64 bit machine, I had to adjust the minimal heap from 400MB up to 500MB, as pointers need a bit more space and Cassandra ran out of memory with 400MB. I also changed the setting to fix the size of the young generation to 100MB with the -Xmn option (above, I haven’t specified it, which lead to different sizes for the default and the CMS garbage collections). In addition, I used the option -XX:ParallelCMSThreads=4 to restrict the number of threads used in the incremental CMS to 4 (the server had 8 available cores).
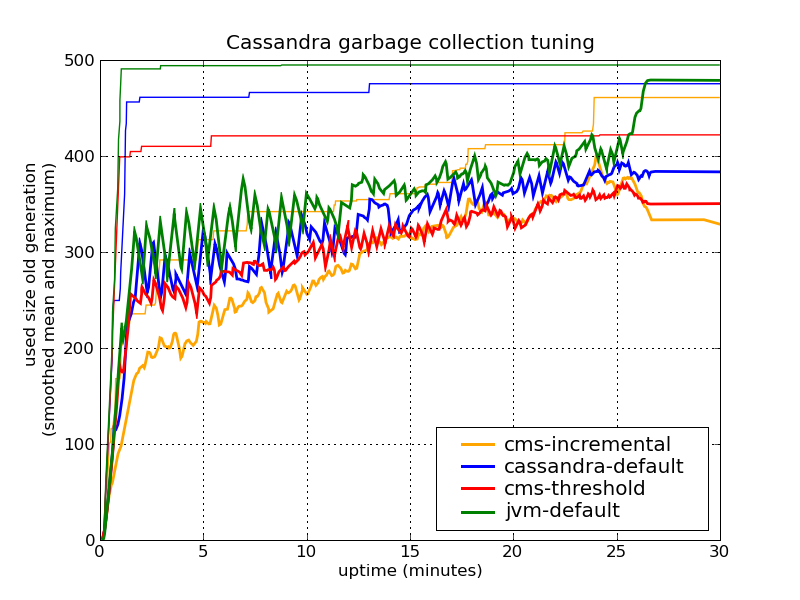
Here are the results for the heap (mean averaged over 60 seconds):
And the results for the CPU load (running average over 30 seconds):
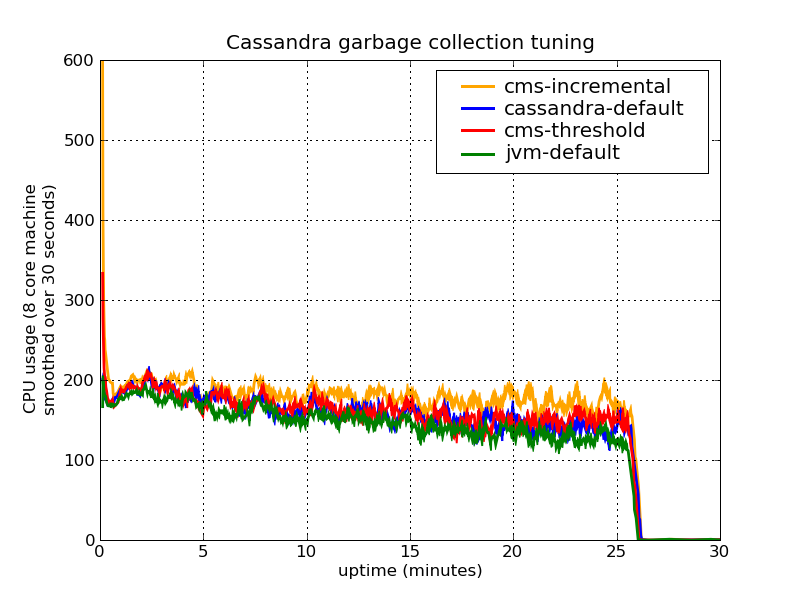
As you can see, the incremental version does not perform as good as in the original case above (apart from the 32 bit vs. 64 bit distinction, I used the same version of the JVM. However, the server was about twice as fast which probably lead to different overall timings.)
Fixing the size of the young generation also reveals that the JVM default GC does not performs as well as the others. Still, the setting with lower CMS threshold performs best. Also if you look at the CPU charts, the incremental CMS leads to only slightly larger CPU load, but it doesn’t really look like it is statistically significant.
One final remark with the CMS threshold: You should of course make sure that the CMS threshold is larger than the normal heap usage. As the size of used heap increases as you add more data (index tables growing, etc.), you should check from time to time if you have enough memory. Otherwise, you will get continuous triggering of the CMS collection.