Java Integration in JRuby
Update: See also the updated entry in the JRuby wiki here.
JRuby has some very nice features to make accessing Java easy, but unfortunately, documentation about these features is a bit hard to come by. Existing documentation is sometimes a bit out-dated, or doesn’t cover all features. The ultimate documentation is of course the source code itself, in particular rspec code to be found in spec/java_integration in the jruby-trunk, but reading source code is maybe not the first choice for everybody when trying to learn a new feature.
Fortunately, Java integration in JRuby is actually pretty good and useful. JRuby does quite a few tricks to make Java classes feel more Ruby-like, for example, by translating between javaNamingSchemes and ruby_naming_schemes, or by automagically converting blocks to implementations of the appropriate Java interfaces, to the effect that you can pass a block to a Java method whenever it expects a Runnable, for example.
I personally think there is great potential in this kind of bilingual development approach which uses Java for all the computationally expensive details and Ruby for the dynamic high-level plumbing. Compared with the Ruby/C alternative, probably based on tools like Swig for the plumbing, JRuby/Java is much easier and cleaner. For example, you can easily deal with Java exceptions on the Ruby side, and even if you don’t you get a call stack with Ruby and Java classes happily mixed when an error occurs.
So I hope that the following is both helpful and correct enough to be of use for others.
The Basics
The first thing to do is to require 'java'. I’m not sure if this is
strictly necessary as many things also work without that, but I guess
it’s safe to do this for the future.
The first question is of course how to access Java classes.
There seem to be several different alternatives for naming a Java
class. The most “ruby-esque” way looks like this: java.lang.System
becomes Java::JavaLang::System. The prefix is always Java::,
followed by the package names with dots turned into CamlCase notation
and finally, the class itself.
If the top-level package is java, javax, com, or org, you can
also access it just like in Java, for example, by typing
java.lang.System. If you want to have this functionality for your
own packages as well, because they start (for example) with edu, you
can use the following code taken from
path-to-jruby-installation/site_ruby/1.8/builtin/javasupport/core_ext/kernel.rb:
def edu
JavaUtilities.get_package_module_dot_format('edu')
endOr, which is even simpler
def edu
Java::Edu
endJava’s primitive types can be found directly in the Java module: For
example, long is Java::long (but not java.long). Actually, I
cannot think of too much you could do with these objects. But you need
them when you want to create primitive arrays. For example,
Java::long[10].new creates a new array of long integer values.
Loading jar-files
If you want to access classes beyond Java’s own runtime, you have to
load the jar file in JRuby. One way to do this is to explicitly
require the jar-file. You can supply a full path, or you can just pass
the jar file which is then searched according to the RUBYLIB
environment variable.
Alternatively, you can put the jar-file into your CLASSPATH. Then, you
can directly access your classes without an explicit require.
Calling Java Methods
You can then access the methods just as in Java, for example
java.lang.System.currentTimeMillisbut JRuby also provides transformed method names to make them more similar to Ruby naming conventions. The typical CamelCase is converted to underscores. The call above can therefore also be written as
java.lang.System.current_time_millisMoreover, JRuby maps the bean conventions as follows
obj.getSomething() becomes obj.something
obj.setSomething(x) becomes obj.something = x
obj.isSomething() becomes obj.something?
When accessing methods, or constants, you have to follow the usual
Ruby conventions. That is, constants have to be accessed by
Class::Constant (for example, JFrame::EXIT_ON_CLOSE), and it seems
you cannot access member variables of objects in Ruby outside of the
object’s methods, even if it is declared public in Java.
For each Java object there are number of methods defined, but most of
them aren’t documented anywhere. I think the more useful ones are
java_class (because the plain class only returns some JRuby-side
proxy object) and java_kind_of?, which I assume is like instanceof
for Java objects.
Conversion of Parameters
When calling a Java method, JRuby goes through some pain of mapping
JRuby types to Java types. For example, if necessary, a Fixnums is
also converted to a double, and so on. If this fails and JRuby does
not find a corresponding method, it prints an error message along the
lines of "no foo with arguments matching [class org.jrub.RubyObject]
on object #<Java::...>". Actually, I think JRuby could be a bit more
helpful here and tell you what class the ruby object was. In any case,
when this happens it means that the types you wanted to pass couldn’t
be converted.
JRuby does not automatically try to convert arrays to Java arrays. You
have to use the to_java method for that. By default, this constructs
Object[] arrays. if you want to construct arrays with a given
primitive type, you pass an argument to to_java which can either be a
symbol like :long or :double, or a class. For example,
[1,2,3].to_java becomes an Object[]
[1,2,3].to_java :long becomes long[]
[1,2,3].to_java(Java::long) same thing
Importing Classes and Including Packages
Typing the full name quickly gets old, so you can import classes into modules, and at the top-level.
You might run into slight difficulties with how to name a class. These
functions actually expect a string, but you can also pass the
Java-style fully qualified class name (that is, with package), if the
package starts with java, javax, or one of the other default package
names. However, currently (at least as of 1.1.5) it seems that you
cannot use the Java::... notation if the top-level package isn’t one
of those for which you could have used the Java-style name anyway. So
I guess it’s save to go with the strings in that cases.
This means that you can do
import java.lang.Stringbut not
import Java::EduSomeuniversity::SomeClassInstead, you should type
import 'edu.someuniversity.SomeClass'or do the def edu; Java::Edu; end hack and then import
edu.someunversity....
While you can import classes into modules and at top-level, you can include whole packages into classes or modules. For example,
module E
include_package javax.swing
endMakes all of Swing available in E and also as, for example,
E::JFrame. At least it used to be like this, currently (in 1.1.5)
E::JFrame gives an odd "wrong number of arguments (1 for 0)"
error… .
Currently, there is no way to import whole packages at the top-level (or at least none I’m aware of). Taking the short-cut through a module and then including the module at top-level currently also doesn’t work. You have to access the class first through the module before you can use it a top-level.
Implementing Java Interfaces and Adding Syntactic Sugar to Java Classes in Ruby
Classes are always open in Ruby. This means that you can add methods
later just be re-opening the class again with a class Name ... end
statement. This is a nice way to add, for example, syntactic sugar to
your Java classes like operators, or other methods like each to make
your classes behave more Ruby-like.
Of course, these additions are only on the Ruby side, and not visible from the Java side. You have to remember that Java is a statically typed language and these run-time additions aren’t visible. Still I found this feature to be tremendously useful for making Java classes more usable on the JRuby side.
What is possible, though, is to implement a Java interface with a JRuby class and pass that new class back to Java. The preferred way to do this is by including the interface in the class definition:
class MyLittleThread
include java.lang.Runnable
def run
10.times { puts "hello!"; sleep 1 }
end
endThen you can start this thread with
java.lang.Thread.new(MyLittleThread.new).runIf the interface has only a single method, you can even pass a block which then gets automatically converted:
java.lang.Thread.new { 10.times { puts "hello!"; sleep 1} }.startI think this was not possible in earlier versions, but you can also subclass a Java class and pass it back to Java code expecting the super class. This is actually pretty cool, as it means that you can freely intertwine Ruby and Java code.
Collections, Regexs, and so on.
JRuby already adds some syntactic sugar on the JRuby side for Java
collections, regular expressions and so on, to make them more
Ruby-like. For example, Enumerable is mixed in into
java.util.Collection. In addition, JRuby also defines some additional
methods like <<, or +. For all the details, have a look at the files
in JRUBY_DIR/lib/ruby/site_ruby/1.8/builtin/java/.
Exceptions
There isn’t much to say here, only that it’s possible to catch Java
exceptions using Ruby’s begin ... rescue ... end construction.
Summary
We’ve seen that there are some very nice features in the JRuby/Java integration, namely coercing some basic types, automatic conversion between Java and JRuby naming schemes, automatic translation of Bean patterns. You can even implement Java interfaces, providing callbacks to Java code in JRuby code.
Some things are maybe missing (or I haven’t figured them out yet) like a way to import whole packages at the top-level. Sometimes I wished that the conversion between Ruby and Java objects would also be more configurable. But given the enormous speed at which JRuby is progressing, I’m sure that these oddities will be smoothed out soon.
On Relevant Dimensions in Kernel Feature Spaces
I finally found some time to write a short overview article about our latest JMLR paper. It discusses some interesting insights into the dimensionality of your data in a kernel feature space when you only consider the information relevant to your supervised learning problem. The paper also presents a method for estimating this dimensionality for a given kernel and data set.
The overview also contains a few lines of matlab code with which you can have a look at the discussed effect yourself. It all boils down to pictures like these:
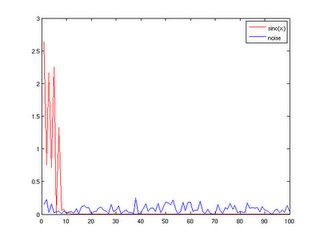
What you see here is the contribution of individual kernel PCA components to the Y samples, divided by the smooth part (red), and the noise (blue), on a toy data set, of course. Kernel PCA components are sorted by decreasing variance. What you can see is that the smooth part is contained in the leading kernel PCA components, while the later components only contain information relevant for the noise. This means that even in infinite-dimensional feature spaces, the actual information is contained in a low-dimensional feature space.
If you are looking for more information, have a look at the overview article, the paper, or a video lecture I gave together with Klaus-Robert Müller in Eindhoven last year. There is also some software available.
Matrices, JNI, DirectBuffers, and Number Crunching in Java
One thing Java lacks is a fast matrix library. There things like JAMA and COLT (not using its LAPACK bindings), but compared to state-of-the-art implementations like ATLAS, they are orders of magnitude slower.
Therefore I’ve set out some time ago to write my own matrix classes based on ATLAS. It turns out that while this is quite straightforward for most of the time, there are few issues which become complicated very quickly, to the point where I wonder if Java is really the right platform for this kind of application at all.
Basically, there are two areas where the Java platform can give you quite a headache:
- Pass large amounts of data to native code.
- Lack of control about how good the JIT compiles code.
Passing Data to Native Code
For a number of reasons, producing highly tuned linear algebra code still requires a lot of low-level fiddling with machine code. If you want really fast code, you have to rely on libraries like ATLAS. The question is then how you pass the data from Java to ATLAS.
Maybe the easiest choice is to store the data in primitive type arrays
like double[] and then access them via JNI. Only that the
documentation is quite
explicit
about the fact that this will not work well for large arrays as you
typically will get a copy of the array, and afterwards, the result has
to be copied back.
The solutions proposed by Sun is to use direct buffers which permits to allocate a piece of memory outside of the VM which is then passed directly to native code.
This was also the solution adopted by our jblas library. However, it quickly turned out that the memory management for DirectBuffers is anything but perfect. As has already been pointed out by others, the main problem is that Java does not take the amount of DirectBuffers into account to compute its memory footprint. What this means is that if you allocate a large number of DirectBuffers, the JVM will happy fill all of your memory, and potentially the swap space without triggering a single garbage collection.
After this happened a few times to me I began wondering whether
DirectBuffers are garbage collected at all, but it seems that
everything is implement reasonably
well: the
memory allocated with direct buffers is managed by PhantomReferences
in order to be notified when the corresponding object is garbage
collected, and if you call System.gc() by hand often enough your
DirectBuffers eventually get garbage collected. That is, most of the
time, at least.
The problem is that there is hardly a way around this. Maybe it’s my fault because direct buffers were never intended to be allocated in large numbers. I guess the typical use would be to allocate a direct buffer of some size and then use that one fixed direct buffer to transfer data between the native code and the JVM.
The only problem is that this is basically the copying scenario which direct buffers should have helped to avoid… .
I’ve written a little program which compares the time it takes to copy an array using the GetDoubleArrayElements() function and using the bulk put and get functions of DoubleBuffer. The results look like this (on an Intel Core2 with 2 GHz):
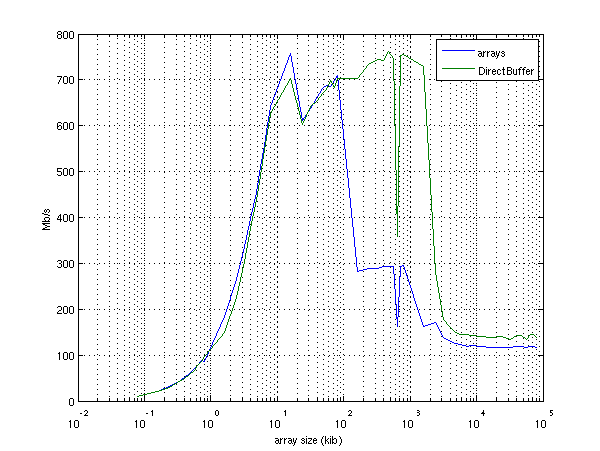
What is a bit funny (and also brings me directly to the second point)
is that GetDoubleArrayElements takes longer than DoubleBuffer.put()
and get() after a size of about 100kb. Both routines basically have to
deal with the same task of copying data from a Java primitive array
into a piece of raw memory. But for some reason, the DoubleBuffer
variant seems to be able to uphold a certain throughput for much
higher amounts of memory.
Code Optimization
The second point basically means that it’s more difficult than in a traditional compile language to control how fast your code becomes after it has been compiled JIT. In principle, there is no reason why this should be true, but I’ve observed a few funny effects which have caused me to doubt that the HotSpot technology is optimized for number crunching.
For example, as I’ve discussed elsewhere, copying data between arrays, or accessing DirectBuffers leads to drastically different performances on the same virtual machine depending on the byte-code compiler. For some reason, the eclipse compiler seems to produce code which leads to much faster machine code than Sun’s own compiler on Sun’s HotSpot JVM.
What this means that it is very hard to optimize code in Java, because you cannot be sure whether it will lead to efficient machine code by the JIT compiler of the virtual machine. With compile languages the situation is in principle similar, but at least you can control which compiler you use and optimize against that.
Summary
So I’m not quite sure what this means. Maybe some JVM guru can enlight me on what is happening here. And I don’t even see what is wrong with the way direct buffers are implemented, but on the bottom line, memory management for direct buffers is not very robust, meaning that your program will typically consume much more memory than it should.