Hipster Scala features
I’m a big fan of Scala, but there are some features I try to steer clear of like covariant or contravariant generics, or excessive use of operator overloading to construct nifty DSLs which look as if a cat walked over your keyboard.
Yesterday a situation like that came up where @thinkberg was looking at my code and said “uh, you’re using +T in a generic”, and I said “that’s a hipster feature of Scala, you don’t need to understand it, you just need to get it right so your code compiles.”
I posted this on Twitter which lead to the comments below. Sometimes I just loooove Twitter ;)
OH: "That's a hipster feature of Scala, you don't need to understand that" ;)
— Doc Brown (@mikiobraun) November 13, 2013
@mikiobraun @jasonbaldridge I understood that feature before it was cool.
— James Iry (@jamesiry) November 13, 2013
@jamesiry @mikiobraun @jasonbaldridge In other words, you got it while it was hot ?
— Francois Garillot (@huitseeker) November 13, 2013
@jamesiry @mikiobraun Poser. I understood it while it was still in the ivory tower. #retrohipster
— Jason Baldridge (@jasonbaldridge) November 13, 2013
@jasonbaldridge @jamesiry You might not have heard of that feature, I wrote it as part of my Ph.D. thesis.
— Doc Brown (@mikiobraun) November 13, 2013
@mikiobraun @jamesiry @jasonbaldridge I already wrote a blog post about how that feature is what's wrong with our industry.
— Eric Sammer (@esammer) November 13, 2013
@yoavgo @mikiobraun I thought hipster features of Scala are called Haskell.
— srockets (@srockets) November 13, 2013
@esammer @jamesiry @mikiobraun @jasonbaldridge If I have to answer ONE more question about that feature on Stack Overflow, I'll go insane!
— Daniel Capo Sobral (@dcsobral) November 13, 2013
@esammer @jamesiry @mikiobraun @jasonbaldridge On related news, I'm betting on structural typing as the hipster feature. :)
— Daniel Capo Sobral (@dcsobral) November 13, 2013
@dcsobral @esammer @jamesiry @mikiobraun @jasonbaldridge Actually, that feature was available in LISP since its first version
— Michael Bar-Sinai (@michbarsinai) November 14, 2013
@michbarsinai @dcsobral @jamesiry @mikiobraun @jasonbaldridge if you really knew c++ you wouldn't want that feature.
— Eric Sammer (@esammer) November 14, 2013
@esammer @michbarsinai @dcsobral @jamesiry @mikiobraun @jasonbaldridge Ada Lovelace already predicted that feature
— Lukas Eder (@lukaseder) November 15, 2013
@michbarsinai @dcsobral @jamesiry @mikiobraun @jasonbaldridge that's just a bad implementation of a monad released in monad.reader 13yrs ago
— Hugo Sereno Ferreira (@ferreira_hugo) November 15, 2013
Edit Nov 18, 2013: Added two more tweets
Designing ML frameworks
Why flexibility and sound design are as important as fast algorithms
As Sam Bessalah pointed out to me below, mlbase already contains some work in the direction of feature management and model selection. Turns out I focussed on MLlib, the low-level layer of mlbase, whereas MLI and MLOpt focus on the higher level parts. I still think that mlbase is rather early stage and need to ramp up on features and flexibility, but they’re definitely heading in the right direction. Unedited original post follows.
As a response to my last post, people mentioned mlbase to me as a potential candidate for bringing scalability and machine learning closer together. I took a closer look and wasn’t really that impressed. Don’t get me wrong, this is not a bad project, but it is still quite early stage. It basically consists of a handful of algorithms implemented on top of the Spark parallelization framework, but lacks most of the infrastructure you need to do proper ML. At the current stage, it’s best to give them some time to mature.
In my view (and I’ve probably implemented 2-3 ML frameworks in the past few years for personal use and spent quite some time in trying to make them flexible and expressive), implementing basic learning algorithms is an important step, but it’s in a way also the simple step. In fact, at TU Berlin we have a lab course each summer, which I designed together with others a few years ago, where we do exactly this: let students implement about a dozen algorithms like PCA, k-means clustering, up to SVMs over the course of the summer semester. (You may find more information in the course notes).
IMHO the real challenges with ML libs are not implementing a bunch of learning algs but tying them together with data handling and preproc.
— Mikio L. Braun (@mikiobraun) September 13, 2013
The hard part is integrating all these learning methods into a whole, aligning interfaces such that similar algorithms can in fact be interchanged flexibly, and also providing meta-algorithms like cross-validation, and in particular feature pre-processings, because you seldom use ML algorithms on the raw data type (usually vectorial) they were originally formulated for.
To give you an idea of the complexities involved, let us consider the following example: You want to learn to automatically tag some text documents using an SVM (support vector machine), a standard learning algorithm which scales quite well (in an entirely pre-Big Data-y kind of sense). The problem is that the SVM is designed for vectorial data, but text is really a string of characters of varying length. So what do you do?
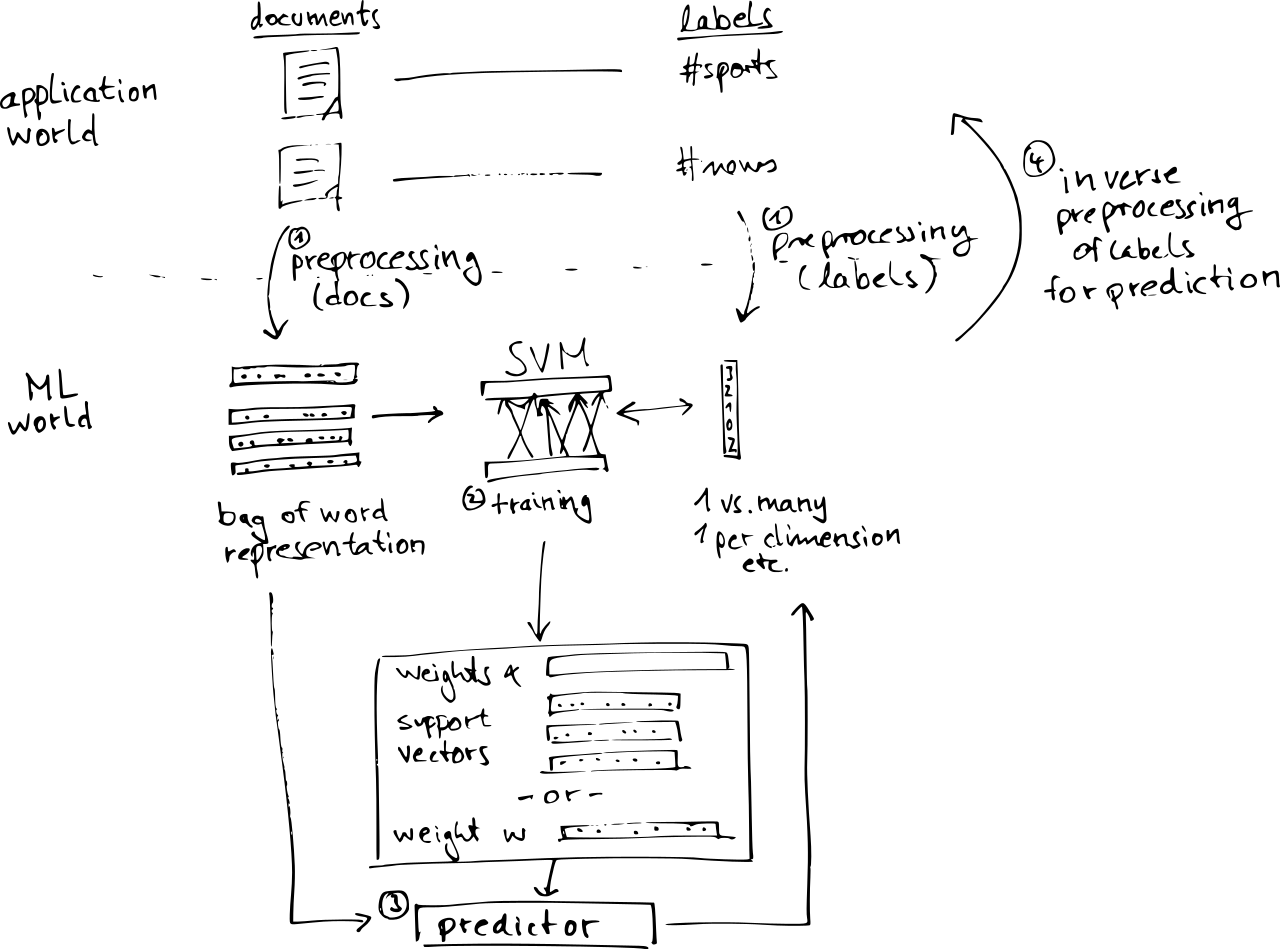
The first step ① in any serious application of machine learning technology is to preprocess your data to obtain a representation which suits the learning algorithm and hopefully still contains the relevant information. For texts, a standard approach is to first do the usually cleaning (removing stop words and stemming words), and then using a bag-of-word representation, where you count how often a word occurs in a document, and then use this collection of counts as a representation of the documents contents. These can be interpreted as sparse vectors in a high-dimensional state, with one dimension for a word.
Depending on your setting, you might also have to preprocess your labels (the tags you wish to predict). Most ML methods are designed for deciding between two classes only, so if you have more classes, you have to use one of a number of approaches, for example, extracting for every label value a data set to distinguish the chosen class from all the others.
Next ② is the actual learning step. This might also involve cross-validation to choose free parameters like the amount of regularization or the parameter of a kernel function (ok, for text classification, you’d usually use a linear kernel which has no parameter).
The output of that training step are the parameters used in the predictor ③. But you cannot directly use the predictor on documents because the predictor operates on the transformed spaces. In order to predict for a new text, you have to first transform the documents into the bag-of-word representation, but you also have to do the inverse mapping for the predicted labels ④ to get back to the actual document tags (and not whatever transformation you have used to break down the learning task into 2-class problems).
In a framework, you’d of course want these different pieces to be freely pluggable and interchangable. You’d want to have an abstraction for a learner such that you can use a generic cross-validation procedure, but you’d also want to have preprocessing operations which you can either run in batch to transform your training data, but also to apply the transformations online in the prediction step.
You also want your preprocessing steps be functional in the sense that you can take a learning algorithm like the SVM in its raw form working on vectorial data and map it to one which can work on text. As you can imagine, there’s a lot of interface defining, generic type designing, and so on to be done.
Getting this part right is at least half of a good (or even great) ML framework, besides having learning algorithms which are fast and powerful.
Data Base vs. Data Science
One thing which Big Data certainly made happen is that it brought the database/infrastructure community and the data analysis/statistics/machine learning communities closer together. As always, each community had it’s own set of models, methods, and ideas about how to structure and interpret the world. You can still tell these differences when looking at current Big Data projects, and I think it’s important to be aware of the distinctions in order to better understand the relationships between different projects.
Because, let’s face it, every project claims to re-invent Big Data. Hadoop and MapReduce being something like the founding fathers of Big Data, other’s projects have since appeared. Most notably, there are stream processing projects like Twitter’s Storm who move from batch-oriented processing to event-based processing which is more suited for real-time, low-latency processing. Spark is yet something different, a bit like Hadoop, but puts greater emphasis on iterative algorithms, and in-memory processing to achieve that landmark “100x faster than Hadoop” every current project seems to need to sport. Twitter’s summingbird project tries to bridge the gap between MapReduce and stream processing by providing us with a high-level set of operators which can then either run on MapReduce or Storm.
However, both Spark or summingbird leave me sort of flat because you can see that they come from a database background, which means that there will still be a considerable gap to serious machine learning.
So what exactly is the difference? In the end, it’s the difference between relational and linear algebra. In the database world, you model relationships between objects which you encode in tables, and foreign keys to link up entries between different tables. Probably the most important insight of the database world was to develop a query language, a declarative description of what you want to extract from your database, leaving the optimization of the query and the exact details of how to perform them efficiently to the database guys.
The machine learning community, on the other hand, has it’s root in linear algebra and probability theory. Objects are usually encoded as a feature vector, that is, a list of numbers describing different properties of an object. Data is often collected in matrices where each row corresponds to an object, and each column to a feature, not much unlike a table in a database.
However, the operations you perform in order to do data analysis are quite different from the data base world. Take something as basic as linear regression: your try to learn a linear function $f(x) = \sum_{i=1}^d w_ix_i$ in a $d$-dimensional space (that is, where your objects are described by a $d$-dimensional vector) given $n$ examples $X_i$, and $Y_i$, where $X_i$ are the features describing your objects and $Y_i$ is the real number you attach to $X_i$. One way to “learn” $w$ is to tune it such that the quadratic error on the training examples is minimal. The solution can be written in closed form as \(w = (X X^T)^{-1}X Y\) where $X$ is the matrix built from the $X_i$ (putting the $X_i$ in the columns of $X$), and $Y$ is the vector of outputs $Y_i$.
In order to solve this, you need to solve the linear equation $(X X^T)w = XY$ which can be done by one of a large number of algorithms, starting with Gaussian elimination, which you’ve probably learned in your undergrad studies, or the conjugate gradient algorithm, or by first computing a Cholesky decomposition. All of these algorithms have in common that they are iterative. They go through a number of operations, for example $O(d^3)$ for the Gaussian elimination case. They also need to store intermediate results. Gaussian elimination and Cholesky decomposition have rather elementary operations acting on individual entries, while the conjugate gradient algorithm performs a matrix-vector multiplication in each iteration.
Most importantly, these algorithms can only be expressed very badly in SQL! It’s certainly not impossible, but you’d need to store your data in much different ways than you would in idiomatic database usage.
So it’s not about whether or not your framework can support iterative algorithms without significant latency, it’s about understanding that joins, group bys, and count() won’t get you far, but you need scalar products, matrix-vector and matrix-matrix multiplications. You don’t need indices for most ML algorithms, maybe except for being able to quickly find the k-nearest neighbors, because most algorithms tend to either take in the whole data set in each iteration or otherwise stream the whole set by some model which is iteratively updated like in stochastic gradient descent. I’m not sure project like Spark or Stratosphere have fully grasped the significance of this yet.
Database infrastructure-inspired Big Data has it’s place when it comes to extracting and preprocessing data, but eventually, you move from database land to machine learning land, which invariably means linear algebra land (or probability theory land, which often also reduces to linear algebra like computations). What often happens today is that you either painstakingly have to break down your linear algebra into MapReduce jobs, or you actively look for algorithms which fit the database view better.
I think we’re still at the beginning of what is possible. Or to be a bit more aggressive, claims that existing (infrastructure, database, parallelism inspired) frameworks provide you with sophistic data analytics are widely exaggerated. They take care of a very important problem by giving you a reliable infrastructure to scale your data analysis code, but there’s still a lot of work that needs to be done on your side. High-level DSLs like Apache Hive or Pig are a first step in this direction but still too much rooted in the database world IMHO.
In summary, one should be aware of the difference between a framework which mostly is concerned with scaling, and a tool which actually provides some piece of data analysis. And even if it comes with basic database-like analytics mechanisms, there is still a long way to go to do some serious data science.
That’s why we’re also thinking that streamdrill occupies an interesting spot, because it is a bit of infrastructure, allowing you to process a serious amount of event data, but it’s also provides valuable analysis, based on algorithms you wouldn’t want to implement yourself, even if you had some Big Data framework like Hadoop at hand. That’s an interesting direction I also would like to see more of in the future.
Note: Just saw that Spark has a logistic regression example on their landing page. Well, doing matrix operations explicitly via map() on collections doesn’t count in my view ;)