Streamdrill examples: e-commerce trending
Talking with people we realized that they find it hard to wrap their heads around what you could do with streamdrill and how you would do it. So we thought we start putting a few examples up here to give you an idea where you could use streamdrill. We’re seeing such opportunities daily, and of course we’d like to get you to the same point ;)
Consider a simple web shop site (not necessarily written in php as indicated in the image below). You want some basic trending on the stuff people are looking at and buying. It generates two kinds of events: views and purchases. We can put a bit more structure in there like categories or makers to be able to drill down on the results later.
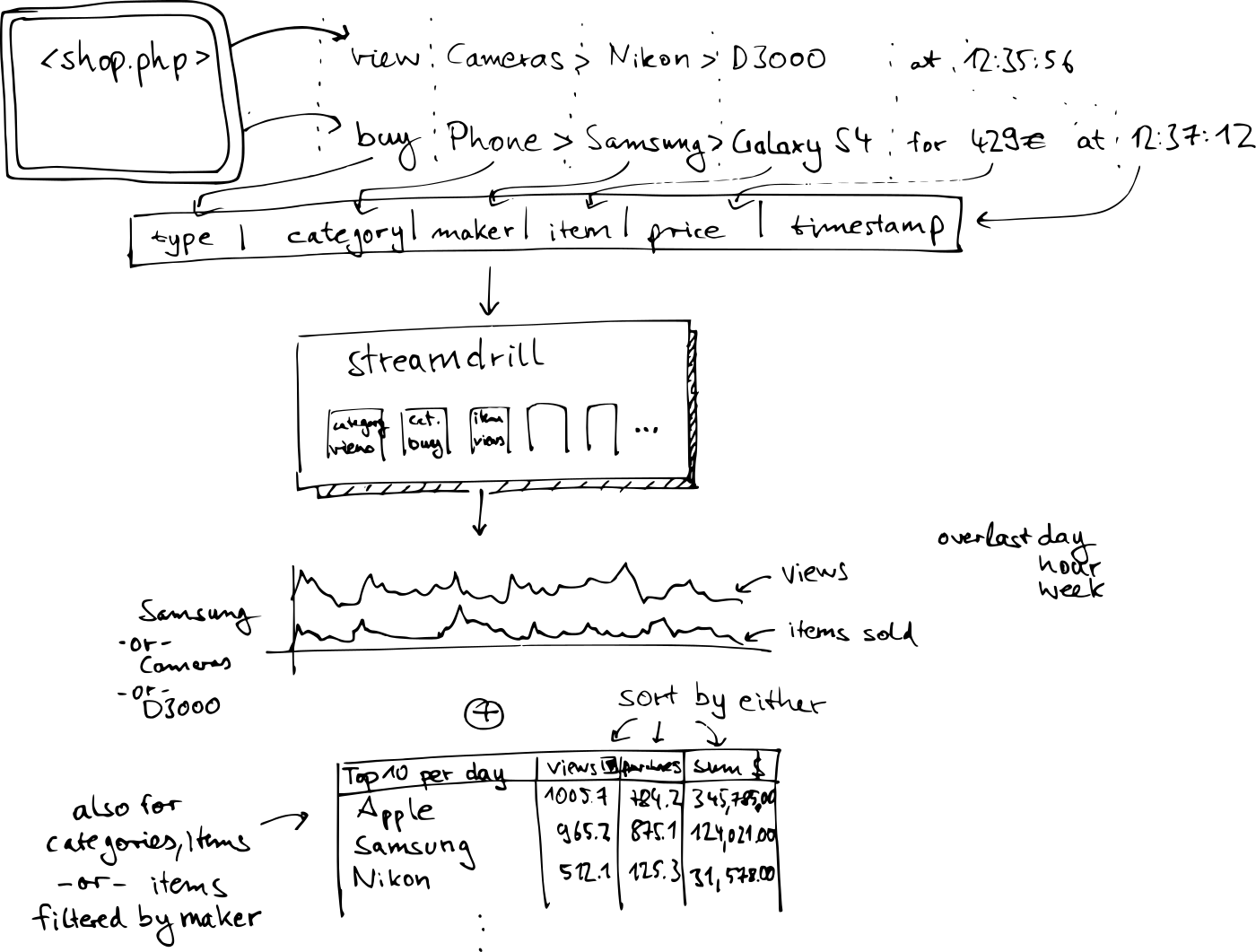
You pipe all the relations you are interested in to streamdrill. In the current version where everything is still pretty raw and basic, you’d need to do this by hand. For example, you define the following trends:
- A full trend which gets the raw events: (type, category, maker, item, price)
- Trends for (type, category), (type, maker), to directly get aggregates for the categories and makers for views and purchases.
- Possibly a two versions of each trend, one where you just count occurrences and one where you put in the price to get in the aggregate revenue earned for a segment or price.
From that you get two things:
The individual activity over the last hour, day, or week so that you can compare categories, makers, and items against one another.

Instant trends showing which are the top categories, makers, and items by views, purchases, and revenue, with the ability to drill down items by maker, and categories and so on.
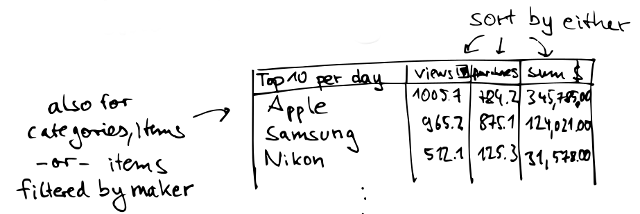
You could also do this kind of analysis with batch SQL SELECT count(*) statements running every few minutes, but you probably don’t want to run this on the main database which you also use for storing your transactions (depending on your output, these select statements might take quite some time). Instead, you set up streamdrill once and then pipe the relevant relations into it. Go to streamdrill.com and have a look at the demo!
Curation and Collaboration in Science
While I have blogged about these topics before, I’ve tried to stay clear of them for some time, mostly because I’ve come believe that while the peer review system is broken, there is little that can be done, and what can be done would take up too much of my time.
Then I got involved with a few conference reviews like NIPS, or discussions within the JMLR MLOSS editoral board, and it got me thinking again.
As you might know I’m an action editor for the machine learning open source software track for some time now. Lately, I’ve begun to find our function there a bit odd. We lately discussed our policy for handling discussions relying on proprietary, closed-source software. I don’t want to discuss the pros and cons here, you can probably read about that elsewhere.
But the point is, whatever decision we made, we would control the visibility and standing of an open source project in the machine learning community. Accepting a project will give the “JMLR seal of approval” to the project and make it much more known within the community, hopefully leading to wider usage and more interaction with users and possibly collaborators.
But is that really something we can or should decide on? Isn’t the whole idea of open source that you put your project out somewhere and invite people to collaborate? Is it really our job as JMLR MLOSS action editors to decide which projects are worth collaborating and which aren’t? We wish to give a boost to projects we find good, but would we prohibit projects from getting known?
Of course, I’m exaggerating a lot here. Even if they’re not accepted at JMLR, they can build a nice website, get engaged with users, grow if there is an interest in what they’re doing. In a way, we’re just curators, trying to pick out projects which we find worthwhile and use the reach of JMLR to make them better known (and giving an entity which you can cite, but that is a different story).
But what about scientific papers? They form the basis of open, distributed collaboration. Once published, others can build open the results, incorporate them in their own papers, or improve upon them, and so on. This collaboration transcends social, geographical, and even temporal ties. You can extend the work of people you don’t know, who are much higher in the hierarchy and probably wouldn’t talk to you when you met them in person, or who don’t even live anymore, or live on the other side of the planet. I personally think, this way of collaboration is one of the pillars of how science operates.
But how well does it work in practice, today? The difference to the JMLR MLOSS case above is that you not only give a boost to papers you accept, but you also prohibit rejected papers from entering the open collaboration process. Not only does your work not get known to a wider audience, it also lacks the seal of approval of a peer reviewed conference or journal. There exist preprint servers like arxiv, but still, many rejected papers either end up discarded or are resubmitted to another conference after being significantly improved (but this work happens in a non-distributed closed fashion).
When people discuss peer review they mostly talk about its role to filter out work which is below the threshold, and to reduce the amount of work to something you could in principle still keep track of. Those are the roles of a curator, which is an important role. But people forget that given the way it works right now, the curators also have a huge influence on who collaborates with whom on what and that just doesn’t seem right.
The end effect is that the scientific community just doesn’t reach that level of “parallelism” which would be desired. Instead of more or less open collaboration also on fresh and novel approaches beyond social ties, people are forced to work on new ideas in an more or less isolated fashion, and do the marketing work until their results become sufficiently “mainstream” to be accepted at the major conferences and journals in their field.
What we need is a better separation between processes with curate, and those which support open collaboration. We need both, venues which try to take a relevant snapshot of what is worked on right now to make it more widely accessible to the whole community, but also ways to support the way of open collaboration science is built upon.
There are attempts at this, like workshops which are focussed on a specific area and relatively open such that everyone can at least get a poster. There are “negative results” kind of workshops aimed at making those results known which are hard to publish. But these things don’t have the same standing as a “real” publication because we let our work still be measured in terms of success at curation type venues, which shifts the focus in unhealthy ways away from doing actual proper scientific work.
The Real-Time Big Data Landscape
The number of companies startups working in the real-time big data space is pretty stunning (including ourselves). But if you look closely, you see that there are quite a few number of ways to approach that problem. In this post, I’ll go through the different technologies to try to draw a real-time big data landscape.
Unfortunately, real-time has come to mean a lot of things, mostly that “it’s fast”. For this post, let’s focus on event data. It’s probably possible to talk about real-time for more or less static data (like crawled web pages), where “real-time” would then mean that it’s fast enough for interactive queries. In that sense, Google search is probably the biggest real-time big data installation.
So back to event data. To have a common ground, let’s consider this setting: You have some form of timestamped event data (user interactions, log data, sensor data), and you’re interested in counting activities over different time intervals. For example, you’re interested in the most retweeted picture over the last 24 hours, or the average temperature in your cluster for the last hour. Let’s also add the possibility of filtering these counts (only users from Germany, only clusters in that rack, etc.) Much more complex applications are thinkable, of course, but already this tasks allows us to see differences between the different approaches.
In the following, we start with a relational (single server) database as the baseline and then discuss different techniques used to make the system faster. Note that real-world systems often employ a mixture of techniques.
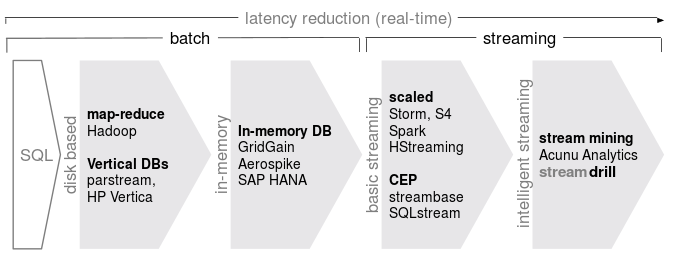
I admit that this image simplifies a lot, it is neither chronologicall accurate, nor does accurately reflect the relationships, but I think it serves as a good big picture to roughly order the different approaches in terms of deviation from the baseline which we’ll handle next:
The Classical Approach: Relational Databases
As a starting point, let’s take a classical relational database. You would
continually insert new events and use queries like SELECT count(*) FROM
events WHERE timestamp >= '2013-06-01 00:00' AND timestampe < '2013-06-02
00:00'.
This is a perfect approach and works well until you have a few million entries in your database. The main problem here are that the database gets slower and slower as you add more data, and that the queries always run a full scan over a significant part of your data set. At some point, these two effects start to amplify one another: Your queries will be slow because there is so much data and inserts become slow because queries are constantly running.
Finally, operations are slow since they are eventually disk based. Even if you factor in caching and RAIDed disks, you won’t be able to go beyond a few hundred inserts per second.
Clustering, Map-Reduce and friends
So if a single server is too slow, let’s make it faster by parallelizing. Luckily, many operations can be parallelized, often even with linear gain in the number of nodes. MapReduce falls into this category, as most NoSQL approaches (although they don’t always come with the query capabilities).
While this approach can lead to impressive performance, there are also a number of things to be considered: Going from a single server to a cluster of servers has some initial performance hit due to network latency, data transfer costs, etc., such that there exists something like a minimum viable cluster size below which the system is not faster than a single server. It might be quite expensive to scale to real-time. Also, as data is constantly growing, one has to keep adding servers to keep the performance on a stable level. The computation is still batch in nature, which means that queries need some time to compute and are therefore not based on the most recent data. There is significant latency in the results.
Hadoop is the most prominent example in this category.
Vertical Databases
One problem with classical databases is that the data is usually stored by rows. So if you want to aggregate over one of the columns (for example, for counting events conditioned on the value in a column), you have to either load a lot of extra data, or you have to do a lot of seeking to only read the required columns.
Vertical databases store the data by columns, so that one can quickly scan all the values of a column. It’s a bit as if one only keeps secondary indices and discards the actual data. One could also store each column in sorted order (keeping pointers so that one can reconstruct the rows if needed), which make range queries even more efficient.
This is an interesting approach, mainly geared at improving disk performance.
Parstream, Shark, Cloudera Impala, HP’s Vertica, and Teradata Aster are examples in this category.
In-Memory
If disk access is the main problem, why not move everything to memory? Together with clustering, and the availability of machines with hundreds of GB of main memory, one can achieve impressive performance improvements (1000 times and more) over disk based systems. Such approaches can also be combined with clustering or vertical storage schemes.
The downside is, of course, that RAM is quite expensive still.
Examples are GridGain, SAP’s HANA.
Streaming
The approaches we have discussed so far are all essentially batch in nature. This gives great flexibility in the queries, but computing results requires a lot of resources. Another approach is to process the event stream as it comes in, aggregating relevant statistics in a way which can later be queried. Results will always be based on the most recent data. This can naturally be combined with clustering to scale the performance.
One issue here is how to make the results of the computation queryable. This usually means that you need some (scalable) storage on the side where you put the results, which adds to the complexity of the installation.
Examples are Twitter’s Storm, Spark, or HStreaming or MapR, which both build this kind of streaming technology on top of Hadoop.
Complex Event Processing (CEP)
CEP is not a performance technique per se but rather a SQL-like query language for streams, which makes it easier for you to work with these systems, as the actor based concurrency model which you find in Storm or others takes a bit of getting used to. Such systems are usually in-memory, and don’t necessarily provide clustering.
I’m also listing this here because CEP systems predate the current Big Data hype.
On the other hand, CEP systems have problems aggregating information over very large spaces. They work best for aggregating a number of key statistics (up to a few hundred) from massive event streams.
Examples include SQLStream, or Streambase, which was aquired by Tibco announced just yesterday.
Approximate Algorithms
So far, all the techniques focus on improving performance through parallelization, using faster storage, or precomputing queries in a streaming fashion. But all these methods don’t touch the original counting task.
Approximate algorithms change that by not giving exact results but trading accuracy for resource usage. I’ve already blogged a lot about stream mining algorithms which do exactly that. Count-min sketches, for example, compute approximate counts using hashing techniques and are able to approximate counts for millions of objects using only very little memory. Moreover, as you supply more memory, results become more exact. These systems are usually in-memory, and also don’t necessarily provide clustering.
The downside here is, of course, that results are no longer exact, which might be either be perfectly ok (e.g. trending topcis) or a dealbreaker (e.g. billing).
Approximate Algorithms are also not strictly restricted to stream processing approaches, you can also use them in a batch fashion to run on data. For example, Klout has a collection of user defined functions to use with Hadoop.
Examples here are our own streamdrill, and Acunu Analytics.
What it says on the box vs. what’s inside the box
Real-time Big Data is an important topic which generates quite a lot of buzz right now. But on closer inspection, there are many different approaches which all have different characteristics when it comes to cost, scalability, latency, and exactness. I think these differences are important when it comes to deciding which solution is the best fit for your specific application, so it’s good to be aware of the differences.