
What is streamdrill good for?
A few weeks ago, we released the beta (oh, sorry, the "β") of streamdrill. One question we heard quite often "Well, what is it good for?" So I'll try to elaborate a bit more on what it does.
First of all, streamdrill is not yet another general purpose big data framework. In it's current version it doesn't even have support for clustering (although that's something we plan to add in the next months).
In a nutshell: streamdrill is usefull for counting activities of event streams over different time windows and finding the most active ones. For the sake of simplicity, let's call the above problem the top-k problem.
So let's break this down a bit.
Event streams are actually common place. Some examples:
- really any kind of server logs
- user interactions in a social network
- logs of web accesses, page impressions, etc.
- monitoring applications of any kind
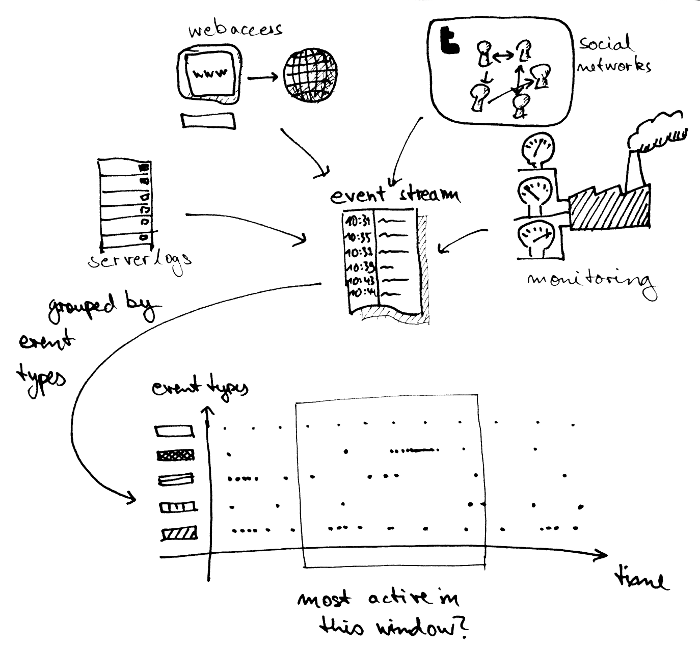
In general, such logs may contain all kinds of data and have varying level of structures, but often it is possible to identify groups of events that have similar structure. For example:
- for server logs: performance reports, errors, exceptions thrown, etc.
- for user interactions: user posting something, user sending messages, etc.
- for web logs: request of page consisting of path, referrer, IP address of the client, user-agent
Such event streams usually contain an enormous amount of data, much too much for a single human being to grasp. As a first step, you're often interested in doing some kind of aggregation, extracting some basic statistics. For example:
- for server logs: what are the average performances over the last hour on average for the whole cluster? Which exceptions are thrown most often?
- for user interactions: which are the most active users? Which media are trending (i.e. viewed/reshared most often)?
- for web logs: which web pages are viewed most often, from which locations? Who are the most active referrers?
This is exactly what streamdrill does. For a given type of event, it counts activities and aggregates them over time windows. Furthermore, it let's you filter results so that you can drill down into your trends.
For streamdrill, an event consists of a fixed number of fields (which are called entities). Currently, they are all just plain strings, but this might change in the future.
For every event, you send an update command to streamdrill which then automatically updates the counts for the timescales configured. These timescales aggregate the counters using a technique called exponential decay counters, which is very memory effective. In addition, streamdrill keeps an ordered index of all entries, such that you can quickly query the most active entries, potentially filtering for some of the entities (for example, only show entires for a given path, user-agent, IP address, etc.)
In the next post, we'll discuss why you would want to use streamdrill for that purpose instead of cooking something up of your own.
Related posts
React to this post
Comments (2)
Sounds cool. What can streamdrill do better than existing event processing engines, e.g. what can I do with streamdrill that I can't do with Esper?
Hi Buki!
I think streamdrill is better at handling really large amounts of data because it is finetuned for the top-k problem. I have another blog post upcoming where I'll talk about the externals. For now, have a look at this page: http://demo.streamdrill.com...
-M