
Designing ML frameworks
As Sam Bessalah pointed out to me below, mlbase already contains some work in the direction of feature management and model selection. Turns out I focussed on MLlib, the low-level layer of mlbase, whereas MLI and MLOpt focus on the higher level parts. I still think that mlbase is rather early stage and need to ramp up on features and flexibility, but they're definitely heading in the right direction. Unedited original post follows.
As a response to my last post, people mentioned mlbase to me as a potential candidate for bringing scalability and machine learning closer together. I took a closer look and wasn't really that impressed. Don't get me wrong, this is not a bad project, but it is still quite early stage. It basically consists of a handful of algorithms implemented on top of the Spark parallelization framework, but lacks most of the infrastructure you need to do proper ML. At the current stage, it's best to give them some time to mature.
In my view (and I've probably implemented 2-3 ML frameworks in the past few years for personal use and spent quite some time in trying to make them flexible and expressive), implementing basic learning algorithms is an important step, but it's in a way also the simple step. In fact, at TU Berlin we have a lab course each summer, which I designed together with others a few years ago, where we do exactly this: let students implement about a dozen algorithms like PCA, k-means clustering, up to SVMs over the course of the summer semester. (You may find more information in the course notes).
IMHO the real challenges with ML libs are not implementing a bunch of learning algs but tying them together with data handling and preproc.
— Mikio L. Braun (@mikiobraun) September 13, 2013
The hard part is integrating all these learning methods into a whole, aligning interfaces such that similar algorithms can in fact be interchanged flexibly, and also providing meta-algorithms like cross-validation, and in particular feature pre-processings, because you seldom use ML algorithms on the raw data type (usually vectorial) they were originally formulated for.
To give you an idea of the complexities involved, let us consider the following example: You want to learn to automatically tag some text documents using an SVM (support vector machine), a standard learning algorithm which scales quite well (in an entirely pre-Big Data-y kind of sense). The problem is that the SVM is designed for vectorial data, but text is really a string of characters of varying length. So what do you do?
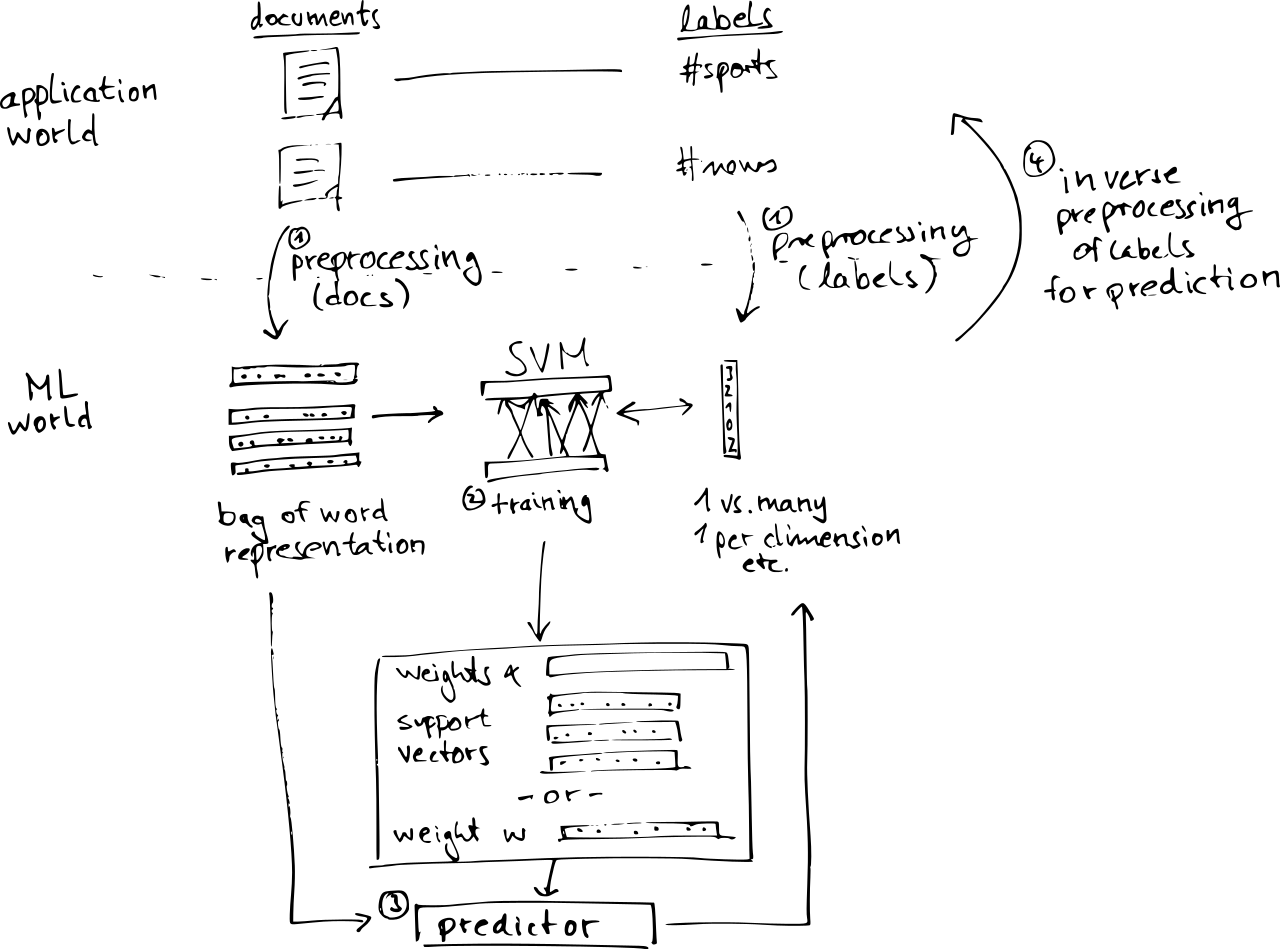
The first step ① in any serious application of machine learning technology is to preprocess your data to obtain a representation which suits the learning algorithm and hopefully still contains the relevant information. For texts, a standard approach is to first do the usually cleaning (removing stop words and stemming words), and then using a bag-of-word representation, where you count how often a word occurs in a document, and then use this collection of counts as a representation of the documents contents. These can be interpreted as sparse vectors in a high-dimensional state, with one dimension for a word.
Depending on your setting, you might also have to preprocess your labels (the tags you wish to predict). Most ML methods are designed for deciding between two classes only, so if you have more classes, you have to use one of a number of approaches, for example, extracting for every label value a data set to distinguish the chosen class from all the others.
Next ② is the actual learning step. This might also involve cross-validation to choose free parameters like the amount of regularization or the parameter of a kernel function (ok, for text classification, you'd usually use a linear kernel which has no parameter).
The output of that training step are the parameters used in the predictor ③. But you cannot directly use the predictor on documents because the predictor operates on the transformed spaces. In order to predict for a new text, you have to first transform the documents into the bag-of-word representation, but you also have to do the inverse mapping for the predicted labels ④ to get back to the actual document tags (and not whatever transformation you have used to break down the learning task into 2-class problems).
In a framework, you'd of course want these different pieces to be freely pluggable and interchangable. You'd want to have an abstraction for a learner such that you can use a generic cross-validation procedure, but you'd also want to have preprocessing operations which you can either run in batch to transform your training data, but also to apply the transformations online in the prediction step.
You also want your preprocessing steps be functional in the sense that you can take a learning algorithm like the SVM in its raw form working on vectorial data and map it to one which can work on text. As you can imagine, there's a lot of interface defining, generic type designing, and so on to be done.
Getting this part right is at least half of a good (or even great) ML framework, besides having learning algorithms which are fast and powerful.
React to this post
Comments (7)
I fully agree on that! I would even go further: I'd suggest a "experiment framework" that allows you to tie task and their dependencies (whether these may be data pre-processing/transformation or visualization tasks such as plotting ap curves). Finally such a framework must support the serialization of the whole experiment graph in order to make an experiment reproducible (you might even go so far to demand for publication of these graphs alongside with your paper...)
Any recommendations on such a framework? :)
You should look at OpenML (http://www.openml.org) which tries to do exactly that.
I should add that I was really thinking more about practical applications and expressiveness. If done right, you have a lot of functionality you can combine to quickly achieve what you need without having to reimplement everything from scratch.
In Python I use scikit-learn (http://scikit-learn.org/sta... and so far, I'm very happy with it.
Yeah, I think most mature ML libs get that right. But some of the hyped new Big Data projects I've seen don't seem to be quite aware of the complexities ahead.
Just discovering this post. But looks like you've described what the MLBASe guys are trying to building. Not just a comprehensive set of algorithms, but a full platform for data processing, model selection and evaluation and all ...
The ampcamp that took place late august had an exercise with Mlbase that looks exactly like what you describe, from processing, featurisation to model selection. you can find it here. http://ampcamp.berkeley.edu...
Hm... actually, I might have been wrong and only focussed on the core part and have overlooked MLI. Which would be very bad ;) Will check and then post an update!
Thanks for the hint!
Hi Sam, so I looked at MLI (and was delighted to see they're using jblas, my Java matrix library ;) They've definitely begun to tackle the important questions. Good thing you pointed this out, I've mostly focussed on MLlib. I'll update the first paragraph above. My bad... .