jblas finally on central Maven repository
![]()
I finally managed to upload jblas to the central Maven respository. In case you don’t know yet, jblas is a fast linear algebra library for Java. It’s unique feature is that it’s based on the optimized ATLAS BLAS and LAPACK libraries. The jar also comes prepackaged with the libraries and automagically extracts the right one depending on your architecture and OS.
The build-process is pretty involved, basically a hand-coded configure-script in Ruby, and a classical Makefile for the native part, some Ant for autogenerating some Java code, and finally some Maven for the final build and packaging.
But all that shouldn’t worry you, because you can now just add the following to your pom.xml and you’re done:
<dependency>
<groupId>org.jblas</groupId>
<artifactId>jblas</artifactId>
<version>1.2.2</version>
</dependency>Download the streamdrill demo
A few days ago, we’ve released the beta version of streamdrill, the real-time event analysis engine which we’ve extracted from our the social media analysis codebase.
The past few days, Leo has been busy working his maven-magic to create a downloadable jar of streamdrill. Just go to streamdrill.com/register and select the “Download” option.
You can then start the jar simply with java. First try
$ java -jar streamdrill.jar -h
to show some of the options, or simply start it with
$ java -Xmx2g -jar streamdrill.jar
to start it on localhost:9669.
Next, get the Python client like this:
$ git clone https://github.com/thinkberg/streamdrill-client.git
and start a example session like this:
$ cd streamdrill-client/streamdrill-python
$ ipython
Python 2.7.3 (default, Sep 26 2012, 21:51:14)
Type "copyright", "credits" or "license" for more information.
IPython 0.13.1.rc2 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]: import streamdrill
In [2]: c = streamdrill.StreamDrillClient("http://localhost:9669")
In [3]: c.create("test", "user", 100, "hour")
Out[3]: u'1c182c7f-40f0-45ca-8d55-7c5fad930173'
In [4]: c.update("test", ["frank"])
In [5]: c.update("test", ["paul"])
In [6]: c.update("test", ["felix"])
In [7]: c.query("test")
[([u'felix'], 1.0),
([u'paul'], 0.9994225441413808),
([u'frank'], 0.998460858626963)]
Some more things to try
help(streamdrill.StreamDrillClient) show some help on the client.
Define a trend with more than one entity:
c.create("page-views", "page:referer", 100, "day")
and query with filter:
c.query("page-views", 10, filter={'page': '/index.html'})
The demo has no restrictions on the analysis features, but you’re not able to take snapshots of your data (so all data is lost on each restart), and you cannot configure the API key and secret, so you’d probably wouldn’t want to use this in production ;)
If you have more questions, don’t hesitate to contact us under info@streamdrill.com.
Announcing Streamdrill
The past few weeks we’ve been busy extracting the real-time engine behind our Twitter analysis stuff, resulting in streamdrill. At heart it is a stream mining algorithm behind a simple REST interface to quickly solve the “top-K problem” of finding the most active items over different timescales in real-time. As usual in stream processing algorithms, events are processed as data comes in such that queries are instantaneous. No more waiting minutes for that map-reduce job to finish, the answer is just there.
In addition, streamdrill employs the kind of automatic resource management I’ve often talked about (for example, here). In this scheme, you specify how many elements you want to keep in memory and least active entries are replaced to make room for new ones. If you are concerned about the approximative nature of this kind of analysis, be sure to read this blog post where I explain why I believe exactness is not always essential.
So what does it look like? Streamdrill aggregates activities from an event stream. You pipe in your events and get the trends for the different timescales. Events consists of a number of fields we call entities.
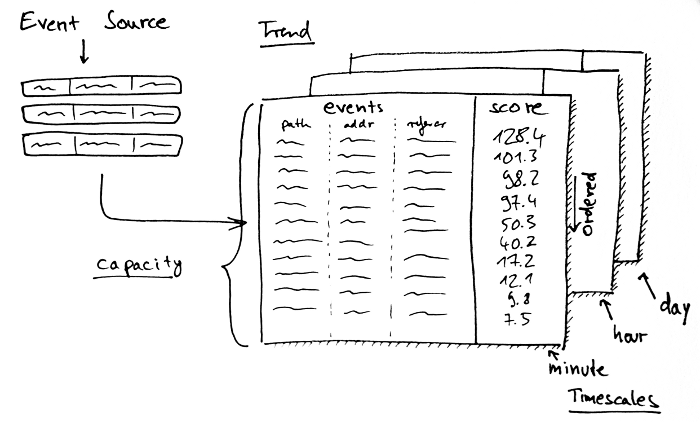
In addition, streamdrill defines indices for the different entities of an event such that you can quickly drill down on your trends.
It’s pretty simplistic, but you can do a lot of stuff with it. All of our Twitter analyses from serienradar to the trends are based on these basic building blocks.
Just to give you an example, it’s really simple to build a basic Twitter retweet analysis using streamdrill.
We get tweets from the public Twitter stream API and extract the id of the retweeted tweet and the user from the data. This only works for API Retweets, but is good enough for this demo. The resulting trend looks like this (go to demo.streamdrill.com for a live demo):
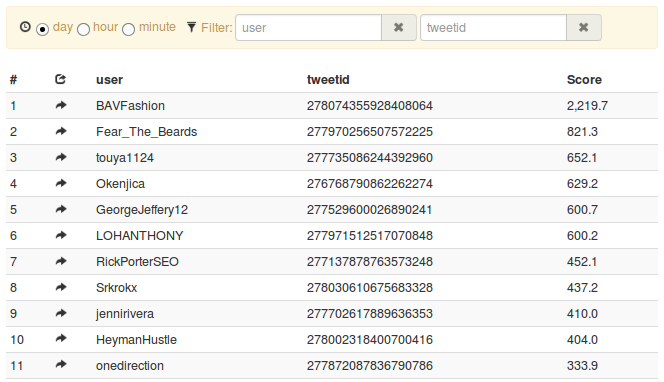
If we filter down on retweets from OneDirection (where is Justin Bieber if you need him?), we get the following list:
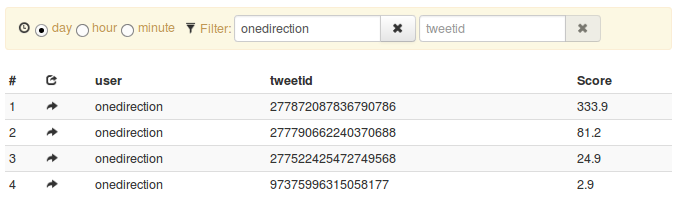
A little feature we’ve built in is the link template where you can display a link in the streamdrill dashboard constructed from the event data (little arrow on the left). In our case, we link back to the original tweet:
UK! RT if you agree that 1D's performance on @thexfactor final made us #ProudDirectioners 1DHQ x
— One Direction (@onedirection) December 9, 2012
(If you wonder about the discrepancy between the counters, we had just restarted the analysis from midnight today, and you only get a subsample of the full feed without paying for it)
So you get a full featured Twitter retweet analysis with a few lines of code, where the hardest part is figuring out Twitter authentication.
We’ve got some Scala and Python client libraries as well as extensive documentation on the demo site. If you’re interested, request a small AWS instance to play around with.