Book review: "Start with Why" by Simon Sinek and Apple's Patent Wars

I recently read “Start with Why” by Simon Sinek which was recommended to me by Paul Bünau. He told me about the book over lunch, and it sounded quite interesting. The basic message is that most people are concerned with what they want to do, or how to accomplish something, but few ask why they should do something.
The book actually takes this a bit further and talks a lot about companies and leadership. Simon Sinek says that companies like Apple manage to have a loyal customer base because they are very clear about why they exist and why they do what they do, and people identify with that very strongly. In the case of Apple, he states that their ‘why’ is to challenge the status quo and to believe in doing things differently. If you’re clear about why you’re doing what you’re doing, it naturally follows how you go about that and also what you do in the end. On the other hand, if companies are unclear about their company vision or their ‘why’, they can only compete on the “what”, which often ends in competing over price, mail-in rebates, and other stuff which only works in the short time.
Other examples are Harley Davidson, Southwest Airlines, Martin Luther King, but also negative examples like Walmart, which used to have a strong sense of why which got deluted when the founder died.
The book is a good read. The basic ideas are explained quite quickly, but the book does a good job of illustrating these ideas in different ways. It felt a bit like a TV show, where once you got acquainted with the main characters, you just go on watching because you want to know how everything turns out.
Of course, the book is simplifies stuff a lot. After all, it’s no sociological theory, it’s about inspiring people to rethink what’s important to them, which is nice.
Taking the example of Apple, I also think it sheds an interesting light on the current patent wars between Apple and Samsung. If Apple’s ‘why’ is really all about innovation and disrupting the status quo, why are they so concerned about other companies eventually copying their products. I think it’s just natural and to be expected. If innovation is really their strong point and they have a loyal fanbase which will buy their products no matter what, as a way that of identifying with Apple’s ‘why’, why are they so concerned that other people are copying them.
Of course, (and this is also discussed in the book), you can’t just survive on the die-hard fans, but you need to products become mainstream. But I guess Apple is still making enough money. It could always be more, but well… .
So these patent wars don’t quite align with the way Apple is portrayed in the book. And I don’t think its the new management. Steve Jobs was infuriated about Android based smartphones, and was willing to “go thermonuclear war on this”. For the future, it will be interesting to see, whether Apple can stay true to its ‘why’ or just become yet another computer company.
In any case, if you’re going to buy the ebook from Amazon.de and want to
me a favor, you can go through this affiliate link and I’ll get a few
cents ;)
Twitter in 2011 revamped
We did a little revamp of our NIPS demo “2011 - A year of Twitter”. The demo itself was a pure console demo which was nice but not very web friendly.
So we thought about ways to make this data more accessible, and Douwe Osinga (Ex-Googler and currently building of Triposo) came up with the idea to style it after Google trends. So we built trends.twimpact.com. It is basically a searchable interface to the data we’ve collected.
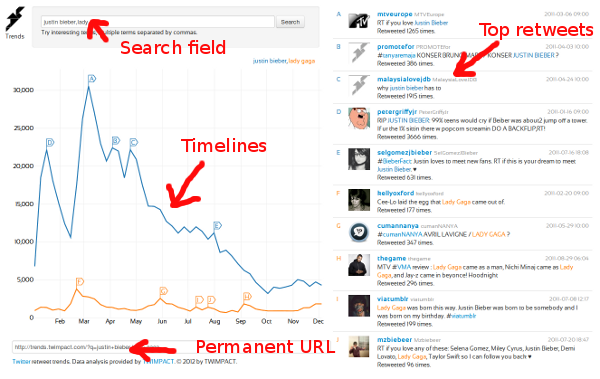
The interface is very simple: You enter search terms (separated by commas) and get the retweet activity for the whole year. On the right, you get the top retweets for the labelled peaks in your data. Below the graph is a text-field which contains the permanent URL for the query, which you can copy and paste to share your findings more easily.
Examples
Here are a few examples (click to go to the website to see the retweets):
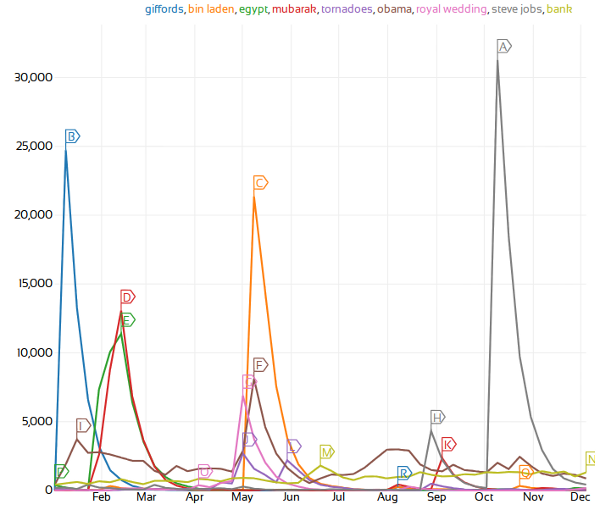
Major events of 2011: Gifford’s attempted assassination, the revolution in Egypt, Barack Obama, the royal wedding, Steve Job’s death, and the banking crisis. If you click the image, it’ll take you to the website itself where you can also see the retweets which are marked.
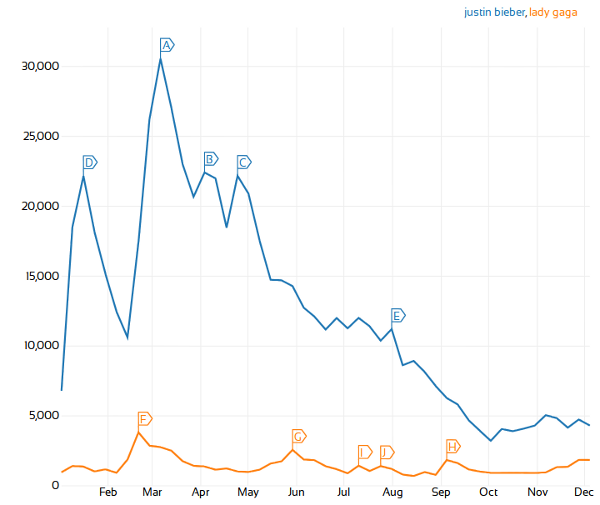
No Twitter analysis is complete without some word on Justin Bieber. Luckily, it seems his influence is on the decline… .
More examples:
- Snow, Tornadoes, and Hurricane: Search terms which have clear seasonal peaks.
- Top movies of 2011: Retweet activity correlates with the box office numbers but probably not as much as you’d expect. Or wouldn’t you?
- Credit cards AMEX retweet games and Visa and Mastercard taking heat because they’re blocking Wikileaks.
- A year of #fail, a year of LOL
- Mobile OSs Updates and the webOS cancelling.
- Some members of the US women soccer’s national team They lost against Japan in the finals, do you remember?
- Holidays in the US
Feel free to add interesting searches below in the discussion section!
Some Background
Some background on the data and the analysis: The data is used from a year of the free Twitter feed, tracking “RT” to get retweets. The free stream is capped at about 50 tweets per second, which still amounts to about 4.3 million tweets per day. The whole raw data for 2011 were about 3.3TB of data (compressed). Using the real-time analysis pipeline we’ve built for TWIMPACT, we did a full retweet analysis, matching also edited retweets, and extracting trends for all kinds of things. We kept a maximum of three hundred thousand most active retweets in memory. All in all, we saw about 5.4 million distinct retweets during the whole time, retweeted by about 35.8 million users.
Originally, for the NIPS demo we wrote snapshots every 8 hours, resulting in about 1000 historic snapshots. For the current demo, we’re using weekly snapshots and converted the original snapshot files to a new format which is based on b-trees giving much faster lookup. There is also a fair amount of caching on several levels.
The full-text index used now is based on Lucene’s tokenizer paired with our own language detector to do the proper stemming on a word level.
Note that we’re not just looking up the whole timelines for the search terms, but really do a full lookup in the full text index for each term and day, and then combine the retweets found to get the result. Otherwise, we couldn’t do queries for more than one search term. So for a search term like “Justin Bieber” this means we’re getting a list of all retweets containing the terms “Justin” and “Bieber”, computing the intersection, and then summing up the scores.
Right now, there are only the 49 weekly snapshots in there (from beginning of January till just before the NIPS conference), amounting to 14.7 million retweets. Together with the indices, the raw data is about 8.5GB served by a single server. We plan to add current data later on, and then also the daily snapshots.
Academia vs. Industry: Explore or Build?
Jay Kreps, a data scientist on LinkedIn’s social network analysis team, posted this tweet which resonated quite much within the Twitter community (133 retweets and 64 favorites so far):
Trick for productionizing research: read current 3-5 pubs and note the stupid simple thing they all claim to beat, implement that.
— Jay Kreps (@jaykreps) July 3, 2012
And the sad thing is, I kind of agree with it, too. There is a little piece of wisdom in the ML community which says that the simple methods often work best. It depends on what different people consider “simple”, but there are enough examples where k-nearest neighbor beats SVMs, linear methods beat more complex ones, or stochastic gradient descent outperforms more fancy optimization methods.
I think the main reason for this divide between science and industry is that both areas have their own, very specific, cost functions to measure progress leading to quite different main activities. In a nutshell: academia explores, industry builds.
The two main driving forces behind scientific progress are “advancing the state-of-the-art” and “novelty”. In my experience, these criteria are much higher on the list than “Does it solve a relevant problem?” And it’s probably also not necessary to be relevant (yet). The standard argument here is number theory which eventually became the foundation for cryptography without which business on the Internet wouldn’t work as it does right now, so we never know, right?
Now if the main forces are improvements over previous work and novelty, what kind of dynamics do we end up with? To me, it increasingly seems like research is about covering as much ground as possible. It’s like performing stochastic gradient ascent with rejection sampling based on the lack of novelty (that is, closeness to existing work). People are constantly looking for ways to find something new, which hopefully opens up new areas to explore.
In the industry, on the other hand, the cost function is different. In the end, it’s all about making money (as we all know). And to make money, you have to create value, in other words, you have to build something.
Of course, exploration is important in the industry as well (and there exist research units within industry whose role is to achieve exactly that), but once you have some interesting new piece of technology, you have to actually first build a product and then a business on that.
Compared to the industry, science also stays on a more abstract level, For example, for machine learning you usually have to describe your algorithm mathematically and implemented it in some preliminary form to run batch experiments, but it is ok to only report the results without publishing your code, too. If you really want to, you can go beyond this kind of research software and make your code usable and release it (and we’ve set up mloss and a special track at JMLR to help you get credit for that), but it’s not strictly necessary.
Of course, both approaches are fully justified and serve different purposes. But I personally think that science is often missing important insights by staying on that abstract level. Only if you really try you ideas in the wild will you see whether your assumptions have been correct or not. The real-world is also an indispensible source for ideas and, of course, gives you a measure of relevance to guide your explorations on a larger scale.
So when we’re talking about relevance and impact of machine learning, I think these issues are also partly due to systemic differences between what kind of work is considered valuable in different communities. I’m not sure there is an easy solution to this. You can personally try to do both, explore and build (and I think there are enough people who do), but that will always mean that you will sacrifice time spent on increasing your score in the other metric.
Thanks to Paul Bünau, Andreas Ziehe, and Martin Scholl for listening to my rambling about this topic over lunch.