Three Things About Data Science You Won't Find In the Books
In case you haven’t heard yet, Data Science is all the craze. Courses, posts, and schools are springing up everywhere. However, every time I take a look at one of those offerings, I see that a lot of emphasis is put on specific learning algorithms. Of course, understanding how logistic regression or deep learning works is cool, but once you start working with data, you find out that there are other things equally important, or maybe even more.
I can’t really blame these courses. I’ve done years of teaching machine learning at universities, and these lectures always focus very much on specific algorithms. You learn everything about support vector machines, Gaussian mixture models, k-Means clustering, and so on, but only when you work on your master thesis do you learn how to properly work with data.
So what does properly mean anyway? Don’t the ends justify the means? Isn’t everything ok as long as I get good predictive performance? That is certainly true, but the key is to make sure that you actually get good performance on future data. As I’ve written elsewhere, it’s just too simple to fool yourself into believing your method works when all you are looking at are results on training data.
So here are my three main insights you won’t easily find in books.
1. Evaluation Is Key
The main goal in data analysis/machine learning/data science (or however you want to call is), is to build a system which will perform well on future data. The distinction between supervised (like classification) and unsupervised learning (like clustering) makes it hard to talk about what this means in general, but in any case you will usually have some data set collected on which you build and design your method. But eventually you want to apply the method to future data, and you want to be sure that the method works well and produces the same kind of results you have seen on your original data set.
A mistake often done by beginners is to just look at the performance on the available data and then assume that it will work just as well on future data. Unfortunately that is seldom the case. Let’s just talk about supervised learning for now, where the task is to predict some outputs based on your inputs, for example, classify emails into spam and non-spam.
If you only consider the training data, then it’s very easy for a machine to return perfect predictions just by memorizing everything (unless the data is contradictory). Actually, this isn’t that uncommon even for humans. Remember when you were memorizing words in a foreign language and you had to made sure that you were testing the words out of order, because otherwise your brain would just memorize the words based on their order?
Machines with their massive capacity for storing and retrieving large amounts of data can do the same thing easily. This leads to overfitting, and lack of generalization.
So the proper way to evaluate is to simulate the effect that you have future data by splitting the data, training on one part and then predicting on the other part. Usually, the training part is larger, and this procedure is also iterated several times in order to get a few numbers to see how stable the method is. The resulting procedure is called cross-validation.
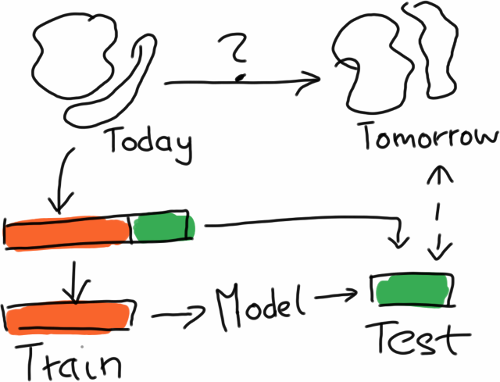 In order to simulate performance on future data, you split the available data in two parts, train on one part, and use the other only for evaluation.
In order to simulate performance on future data, you split the available data in two parts, train on one part, and use the other only for evaluation.
Still, a lot can go wrong, especially when the data is non-stationary, that is, the underlying distribution of the data is changing over time. Which often happens when you are looking at data measured in the real world. Sales figures will look quite different in January than in June.
Or there is a lot of correlation between the data points, meaning that if you know one data point you already know a lot about another data point. For example, if you take stock prices, they usually don’t jump around a lot from one day to the other, so that doing the training/test split randomly by day leads to training and test data sets which are highly correlated.
Whenever that happens, you will get performance numbers which are overly optimistic, and your method will not work well on true future data. In the worst case, you’ve finally convinced people to try out your method in the wild, and then it stops working, so learning how to properly evaluate is key!
2. It’s All In The Feature Extraction
Learning about a new method is exciting and all, but the truth is that most complex method essentially perform the same, and that the real difference is made by the way in which raw data is turned into features used in learning.
Modern learning methods are pretty powerful, easily dealing with tens of thousand of features and hundreds of thousand of data points, but the truth is that in the end, these methods are pretty dumb. Especially methods that learn a linear model (like logistic regression, or linear support vector machines) are essentially as dumb as your calculator.
They are really good at identifying the informative features given enough data, but if the information isn’t in there, or not representable by a linear combination of input features, there is little they can do. The are also not able to do this kind of data reduction themselves by having “insights” about the data.
Put differently, you can massively reduce the amount of data you need by finding the right features. Hypothetically speaking, if you reduced all the features to the function you want to predict, there is nothing left to learn, right? That is how powerful feature extraction is!
This means two things: First of all, you should make sure that you master one of those nearly equivalent methods, but then you can stick with them. So you don’t really need logistic regression and linear SVMs, you can just pick one. This involves also understanding which methods are nearly the same, where the key point lies in the underlying model. So deep learning is something different, but linear models are mostly the same in terms of expressive power. Still, training time, sparsity of the solution, etc. may differ, but you will get the same predictive performance in most cases.
Second of all, you should learn all about feature engineering. Unfortunately, this is more of an art, and almost not covered in any of the textbooks because there is so little theory to it. Normalization will go a long way. Sometimes, features need to be taken the logarithm of. Whenever you can eliminate some degree of freedom, that is, get rid of one way in which the data can change which is irrelevant to the prediction task, you have significantly lowered the amount of data you need to train well.
Sometimes it is very easy to spot these kinds of transformations. For example, if you are doing handwritten character recognition, it is pretty clear that colors don’t matter as long as you have a background and a foreground.
I know that textbooks often sell methods as being so powerful that you can just throw data against them and they will do the rest. Which is maybe also true from a theoretical viewpoint and an infinite source of data. But in reality, data and our time is finite, so finding informative features is absolutely essential.
3. Model Selection Burns Most Cycles, Not Data Set Sizes
Now this is something you don’t want to say too loudly in the age of Big Data, but most data sets will perfectly fit into your main memory. And your methods will probably also not take too long to run on the data. But you will spend a lot of time extracting features from the raw data and running cross-validation to compare different feature extraction pipelines and parameters for your learning method.
 For model selection, you go through a large number of parameter combinations, evaluating the performance on identical copies of the data.
For model selection, you go through a large number of parameter combinations, evaluating the performance on identical copies of the data.
The problem is all in the combinatorial explosion. Let’s say you have just two parameters, and it takes about a minute to train your model and get a performance estimate on the hold out data set (properly evaluated as explained above). If you have five candidate values for each of the parameters, and you perform 5-fold cross-validation (splitting the data set into five parts and running the test five times, using a different part for testing in each iteration), this means that you will already do 125 runs to find out which method works well, and instead of one minute you wait about two hours.
The good message here is that this is easily parallelizable, because the different runs are entirely independent of one another. The same holds for feature extraction where you usually apply the same operation (parsing, extraction, conversion, etc.) to each data set independently, leading to something which is called “embarrasingly parallel” (yes, that’s a technical term).
The bad message here is mostly for the Big Data guys, because all of this means that there is seldom the need for scalable implementations of complex methods, but already running the same undistributed algorithm on data in memory in parallel would be very helpful in most cases.
Of course, there exist applications like learning global models from terabytes of log data for ad optimization, or recommendation for million of users, but bread-and-butter use cases are often of the type described here.
Finally, having lots of data by itself does not mean that you really need all the data, either. The questions is much more about the complexity of the underlying learning problem. If the problem can be solved by a simple model, you don’t need that much data to infer the parameters of your model. In that case, taking a random subset of the data might already help a lot. And as I said above, sometimes, the right feature representation can also help tremendously in bringing down the number of data points needed.
In summary
In summary, knowing how to evaluate properly can help a lot to reduce the risk that the method won’t perform on future data. Getting the feature extraction right is maybe the most effective lever to pull to get good results, and finally, it doesn’t always to have Big Data, although distributed computation can help to bring down training times.
I’m contemplating of putting together an ebook with articles like this one and some hands on stuff to get you started with data science. If you want to show your support, you can sign up here to get notified when the book is published.
Pivoting
To make a long story short, I’ve decided to scale back my involvement with the streamdrill company to a purely advisory role. The reasons for this are naturally very complex, but in the end, I wasn’t seeing the kind of traction or the prospect of traction necessary to keep going at the pace I was going, splitting time between family, the university jobs, which paid my bills, and doing the dev work and marketing for streamdrill.
In fact I still believe the base technology is pretty compelling, so we’re going to open source the core, to allow me to continue to work on it. That’s something I had been wanting to do for some time, because in the Big Data community, having some part as open-source is necessary to get people to try this out. At streamdrill, we always had more of a focus on providing some directly usable end product, so this won’t hurt the company (which Leo is planning to continue.)
So the big question (or maybe not) is what to do now. In fact, I already got plenty to do… .
So I’m still at the TU Berlin, and let me whine about the situation here for one paragraph ;) It’s not ideal. I sort of have accepted for myself that my interests are just too applied for academia (one simply does not write software at my level anymore, people told me it’s suspicious and I should stop it). In terms of career I have moved up to a point where the work I’m expected to do is mostly teaching, advising students, and stuff like grant proposal and project management. And while I seem to do OK, this makes me deal with stuff I find extremely painful. On the plus side, it provides good job security and somewhat fair pay, but that will only get you so far, soulwise.
And the workload is pretty high. I have to do about a professor level of teaching, and am currently supervising about 5 students writing their master thesis and something like two to three Ph.D. students.
I’m sort of managing our side of the Berlin Big Data Center project. Luckily this project aligns well with my interests. It’s about bringing together machine learning people and people who build scalable distributed infrastructure. We’re closely related to the Apache Flink project, which is also really picking up lately. There’s lots of mutual interest, so I’m definitely looking forward to that.
There is also another project which is potentially coming up, so my current workload is two projects, half a dozen students, and about 20 or so students to supervise in four teaching courses.
I’ve recently started to join the InfoQ editorial board and try to cover about one Big Data related news item per week. And I’m again taking part in the 3rd batch of the Data Science Retreat starting in February.
And there’s still more stuff I’m interested in:
- jblas needs some love. My last serious updates are two years old, but with all that JVM based data analysis happening, jblas usage has picked up recently. I have some ideas to unclutter the code, make the whole build process more manageable, and maybe look into some new ideas to make use of native code also in cases where copying would be prohibitive, maybe by using caches or explicit memory handling.
- open source streamdrill, of course. Use of probabilistic data structures are picking up recently, and I always thought that it’s time to take it to the next level and write analysis algorithms which naturally use these structures as building blocks.
- There’s a lot of talk about data science / Big Data convergence, but based on the people who are doing Ph.D.s in machine learning at TU Berlin, the existing technology is still much too unwieldy to use. Ever tried setting up Hadoop from the sources? I simply cannot see that someone who is used to Python would want to do that. Spark, for example, is investing a lot in that area, but their machine learning efforts are still very rough and somewhat premature.
- Likewise, there is a lot of training under way to get more Data Scientists, but I think that the way data analysis is taught at universities is a very bad guideline, because that’s really trying to teach people to become researchers and create new data analysis methods, not use them reasonably. I think similar to the division between people who build tools and those who use tools to do something valuable with it, there needs to be a separation of training programs. And for that existing tools need to mature more. Scikit-learn, for example, is an awesome collection of many, many methods, but it has very little in terms of high-level stuff to support the process of data analysis.
- Notebooks is the new excel. I’m seeing a lot of use of IPython style notebooks lately to get to a more “literal” style of data analysis to get data analysis and business people to collaborate. Also the integration of code, plots, and results is really nice.
- Moving out of out-of-core-learning. After working with streaming for so long, the classical Python/R way of doing data analysis feels so weird. Why do I have to load all that data into memory? I understand that learning methods are so complex and data access patterns so random that this is the only way, but it now feels like a big restriction that your data set needs to fit into memory. Machine learning should be more like UNIX where stuff is file based and 10k C programs can work with gigabytes of data with 32MB of RAM if they need to (ok, I’m thinking of how it was back in 1994, but you get my point). And I’m not simply talking about data science on the command line, we probably need new algorithms for that, too.
And then there are even other odds and bits. I mean why is everything so complex nowadays? Just frameworks wrapping frameworks. CSS frameworks? I mean, c’mon! What about things which did one thing well and weren’t a pain to set up?
I want to keep attending more non-academic meetings. I’ll try to go to QCon London for at least one day, and I’ll be also speaking at Strata in London in May.
Still, the whole situation is hardly ideal. Maybe it’s asking too much of a job to have perfect alignment between interests and job related activities, but I think there’s room for improvement. Stay tuned.
Data Science workshop at data2day

Giving a one day tutorial on data science is something I’ve been considering in different contexts from time to time, but for different reasons it never really happened. Finally, last Friday, the tutorial took place as a workshop in the data2day conference, and I think it went pretty well. In this post I’d like to talk a bit about our approach and our experiences.
The conference was organized by the heise publisher, well known in Germany for their print magazines c’t and iX, which have been household names in IT since the eighties. It was the first conference in the Big Data/Data Science context organized by them, but already brought together over 150 participants.
For the workshop, I was happy to team up with Jan Müller and Paul Bünau from idalab. In fact, Paul and I had developed a similar kind of hands-on introduction to data analysis a few years ago while he was working on his PhD at TU Berlin. Designed as a summer long course, the idea was to have students implement a number of machine learning algorithms themselves. Each method would first be presented by focussing on the main ideas, without going into the theory too much. Then, the students would have two to three weeks time to implement the method and play around with them on some toy data. During that phase, we would have a weekly office hour where we would go around and talk to the students individually to help them where they got stuck.
This course seemed to be quite popular with the students. We would still randomly get praise for the course years later with students telling us that this was among the courses where they learned most.
So when designing this one day workshop, the idea was from the beginning to keep these two ingredients: Focus on main ideas and context, and a hands-on approach.
It was particularly important to us to not just go through a bunch of learning algorithms, but also stress how important is to know what you are doing. As I have discussed before, it is too easy to put together some data analysis pipeline and then not properly evaluate. Everything looks great, but in the end you have just looked at training error, resulting in really bad performance on future data.
For the hands-on part, we chose to work with IPython notebooks. These are available on all major operating systems, notebooks can saved and loaded easily, it integrates with plotting, and so on. Toolwise we chose to work with numpy, pandas, [scikit-learn], and matplotlib. Originally the plan was to have one session where we go through the basics of the tools and then two use cases, but while putting the material together it became apparent that there wasn’t enough time for two use cases, so we just sticked with a simple example based on MNIST character recognition, and decision trees.
So in the end the course went like this:
-
about one hour if introductory course on what is data science/machine learning, and things like supervised vs. unsupervised learning, evaluation, cross-validation, etc.
-
one hour of going through the basics of numpy and pandas in an interactive IPython session
-
one hour of doing some exercises with numpy and pandas
-
another hour of going through an example with scikit-learn
-
two hours of doing the use case
The notebook from the example sessions were handed out at the beginning of the exercises, and the exercises were prepared as IPython notebooks themselves with free cells where you could put down your solutions.
As it is with all such things, you never know whether you thought of everything, but all in all, we felt the workshop went very well. With three of us, there was enough time to help each of the participants individually, including fixing issues like finding out where IPython was keeping it files under Windows, dealing with oddities of Python’s indexing scheme, and so on.
In the end, all participants had a running notebook which loaded the MNIST data, learned a decision tree whose hyperparameter was adjusted by cross- validation, giving them about 83% accuracy. Of course that is not optimal, but already pretty good for a few lines of code. Most importantly, everyone now has a complete framework from which they can start exploring other approaches, try out new methods, and so on.
Next time, we would probably intersperse the background talk with the solutions, such that there isn’t such a monolithic block at the beginning, and be more careful with Python 3 vs Python 2. But overall I think our approach worked out very well (also based on the feedback we got).
The workshop also showed that there is a real need of teaching people the more high level concepts like proper validation. Unfortunately, even at universities, the focus is too much on the methods themselves. Students often learn the process and things like proper validation only when they work on their master thesis. On the hand, for doing robust and reliable data analyses, these things are absolutely essential.