Parts But No Car
What it takes to build a Big Data Solution
One question which pops up again and again when I talk about streamdrill is whether that cannot be done by X, where X is one of Hadoop, Spark, Go, or some other piece of Big Data infrastructure.
Of course, the reason why I find it hard to respond that question is that the engineer in my is tempted to say “in principle, yes” which sort of questions why I put all that work to rebuild something which apparently already exists. But the truth is that there’s a huge gap between “in principle” and “in reality”, and I’d like to spell this difference out in this post.
The bottom line is that all those pieces of Big Data infrastructure which exists today provide you with a lot of pretty impressive functionality, distributed storage, scalable computing, resilience, and so on, but not in a way which solves your data analysis problems out of the box. The analogy I like is that Big Data is a lot like providing you with an engine, a transmission, some tires, a gearbox, and so on, but no car.
So let us consider an example where you have some clickstream and you want to extract some information about your users. Think, for example, recommendation, or churn prediction. So what steps are actually involved in putting together such a system?
First comes the hardware, either on the cloud or by buying or finding some spare machines, and then setting up the basic infrastructure. Nowadays, this would mean installing Linux, HDFS, the distributed filesystem of Hadoop, and YARN, the resource manager which allows you to run different kind of compute jobs on the cluster. Especially when you go for the raw Open Source version of Hadoop, this step requires a lot of manual configuration, and unless you already did this a few times, this might take a while to get to work.
Then, you need to take in the data in some way, for example, by something like Apache Kafka, which is essentially a mixture of a distributed log storage and an event transport plattform.
Next, you need to process the data, which could either be done by a system like Apache Storm, a stream processing framework which lets you distribute computing once you have it broken down to pieces of computation taking in an event at a time. Or you use Apache Spark which let’s you describe computation on a higher level with something like a functional collection API and can also be fed a stream of data.
Unfortunately, this still does nothing useful out of the box. Both Storm and Spark are just frameworks for distributed computing, meaning that they allow you to scale computation, but you need to tell them what you want to compute. So you first need to figure out what to do with your data and this involves looking at data, identifying the kind of statistical analysis which is suited to solve your problem, and so on, and probably requires a skilled data scientist to spend one to two month working on the data. There are projects like mllib which provide more advanced analytics, but again these projects don’t provide full solutions to application problems but are tools for a data scientist to work with (And they are still somewhat early stage IMHO.)
Still, there’s more work to do. One thing people are often unaware of is that Storm and Spark have no storage layer. This means that they both perform computation, but to get to the result of the computation, you have to store it somewhere and have some means to query it. This means usually to store the result in a database, something like redis, if you want the speed of a memory based data storage, or in some other way.
So by now we have taken care of how to get the data in, what to do with it and how, and how to store the result such that we can query it while the computation is going on. Conservatively talking, we’re already down six man months, probably less if you have done it before and/or are lucky. Finally, you also need to have some way to visualize the results, or if your main access is via an API, to monitor what the system is doing. For this, more coding is required, to create a web backend with graphs written in d3.js in JavaScript.
The resulting system probably looks a bit like this.
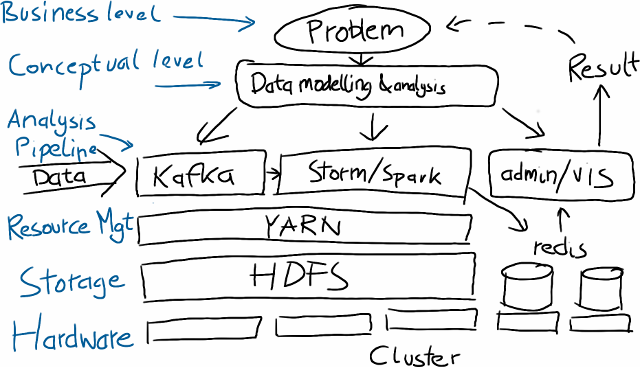
Lots of moving parts which need to be deployed and maintained. Contrast this with an integrated solution. To me this is difference between a bunch of parts and a car.
Big Data & Machine Learning Convergence
More Linear Algebra and Scalable Computing
I recently had two pretty interesting discussions with students here at TU Berlin which I think are representative with respect to how big the divide between the machine learning community and the Big Data community still is.
Linear Algebra vs. Functional collections
One student is working on implementing a boosting method I wrote a few years ago using next-gen Big Data frameworks like Flink and Spark as part of his master thesis. I choose this algorithm because it the operations involved were quite simple: computing scalar products, vector differences, and norms of vectors. Probably the most complex thing is to compute a cumulative sum.
These are all operations which boil down to linear algebra, and the whole algorithm is a few lines of code in pseudo-notation expressed in linear algebra. I was wondering just how hard it would be to formulate this using a more “functional collection” style API.
For example, in order to compute the squared norm of a vector, you have to square each element and sum them up. In a language like C you’d do it like this:
double squaredNorm(int n, double a[]) {
double s = 0;
for(i = 0; i < n; i++) {
s += a[i] * a[i];
}
return s;
}In Scala, you’d express the same thing with
def squaredNorm(a: Seq[Double]) =
a.map(x => x*x).sumIn a way, the main challenge here consists in breaking down these for-loops into these sequence primitives provided by the language. Another example: the scalar product (sum of product of the corresponding elements of two vectors) would become
def scalarProduct(a: Seq[Double], b: Seq[Double]) =
a.zip(b).map(ab => ab._1 * ab._2).sumand so on.
Now turning to a system like Flink or Spark which provides a very similar set of operations and is able to distribute them, it should be possible to use a similar approach. However, the first surprise was that in distributed systems, there is no notion of order of a sequence. It’s really more of a collection of things.
So if you have to compute the scalar product between the vectors, you need to extend the stored data to include the index of each entry as well, and then you first need to join the two sequences on the index to be able to perform the map.
The student is still half way through with this, but already it has cost considerable amount of mental work to rethink standard operations in the new notation, and most importantly, have faith in the underlying system that it is able to perform things like joining vectors such that elements are aligned in a smart fashion.
I think the main message here is that machine learners really like to think in terms of matrices and vectors, not so much databases and query languages. That’s the way algorithms are described in papers, that’s the way people think, and the way people are trained, and it would be tremendously helpful if there is a layer for that on top of Spark or Flink. There are already some activites in that direction like distributed vectors in Spark or the spark-shell in Mahout, and I’m pretty interested to see whether how they will develop.
Big Data vs. Big Computation
The other interesting discussion was with a Ph.D. student who works on predicting properties in solid state physics using machine learning. He apparently didn’t knew too much about Hadoop and when I explained it to him he also found it not appealing at all, although he is spending quite some compute time on the groups cluster.
There exists a medium sized cluster at TU Berlin for the machine learning group. It consists of about 35 nodes, and hosts about 13TB of data for all kinds of research projects from the last ten or so years. But the cluster does not run on Hadoop, it uses Sun’s gridengine, which is now maintained by Univa. There are historical reasons for that. Actually, the current infrastructure developed over a number of years. So here is the short-history of distributed computing at the lab:
Back in the early 2000s, people were still having desktop PCs under their desks. At the time, people were doing most of their work on their own computer, although I think disk space was already shared over NFS (probably mainly for backup reasons). As people required more computing power, people started to log into other computers (of course, after asking whether that was ok), in addition to several larger sized computers which were bought at the time.
That didn’t go well for a long time. First of all, manually finding computers with resources to spare was pretty cumbersome, and oftentimes, your computer would become very noisy although you weren’t doing any work yourself. So the next step was to buy some rack servers, and put them into a server room, still with the same centralized filesystem shared over NFS.
The next step was to keep people from logging in to individual computers. Instead, gridengine was installed, which lets you submit jobs in the form of shell scripts to execute on the cluster when there were free resources. In a way, gridengine is like YARN, but restricted to shell scripts and interactive shells. It has some more advanced capabilities, but people mostly submit it to run their programs somewhere in the cluster.
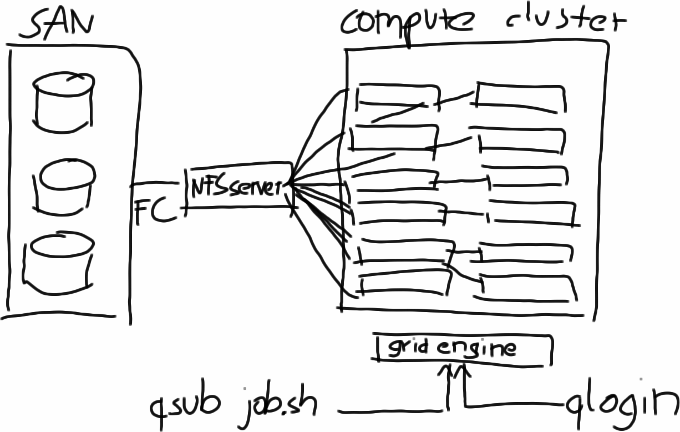 Compute cluster for machine learning research.
Compute cluster for machine learning research.
Things have evolved a bit by now, for example, the NFS is now connected to a SAN over fibre channel, and there exist different slots for interactive and batch jobs, but the structure is still the same, and it works. People use it for matlab, native code, python, and many other things.
I think the main reason that this system still works is that the jobs which are run here are mostly compute intensive and no so much data intensive. Mostly the system is used to run large batches of model comparison, testing many different variants on essentially the same data set.
Most jobs follow the same principle: They initially load the data into memory (usually not more than a few hundred MB) and then compute for minutes to hours. In the end, the resulting model and some performance numbers are written to disk. Usually, the methods are pretty complex (this is ML research, after all). Contrast this with “typical” Big Data settings where you have terabytes of data and run comparatively simple analysis methods or search on them.
The good message here is that scalable computing in the way it’s mostly required today is not that complicated. So this is less about MPI and hordes of compute workers, but more about support for managing long running computation tasks, dealing with issues of job dependency, snapshotting for failures, and so on.
Big Data to Complex Methods?
The way I see it, Big Data has so far been driven mostly by the requirement to deal with huge amount of data in a scalable fashion, while the methods were usually pretty simple (well, at least in terms to what is considered simple in machine learning research).
But eventually, more complex methods will also become relevant, such that scalable large scale computations will become more important, and possible even a combination of both. There already exists a large body of work for large scale computation, for example from people running large scale numerical simulation in physics or meterology, but less so from database people.
On the other hand, there is lots of potential for machine learners to open up new possibilities to deal with vasts amount of data in an interactive fashion, something which is just plain impossible with a system like gridengine.
As these two fields converge, work has to be done to provide the right set of mechanisms and abstractions. Right now I still think there is a considerable gap which we need to close over the next few years.
The Streaming Landscape, 2014 edition: Convergence, APIs, Data Access
A year ago, I wrote a post on the real-time big data landscape, identifying different approaches to deal with real-time big data. As I saw it back then, there was sort of an evolution from database based approaches (put all your data in, run queries), up to stream processing (one event at a time), and finally algorithmic approaches relying on stream mining algorithsm, together with all kinds of performance “hacks” like parallelization, or using memory instead of disks.
In principle, this picture is still adequate in terms of the underlying mode of data processing, that is, where you store your data, whether you process it as it comes in or in a more batch oriented fashion later on, and so on, but there is always the question how to build systems around these approaches. And given the amount of money which is currently infused into the whole Big Data company landscape, quite a lot is happening in that area.
Convergence
Currently, there is a lot of convergence happening. One such example is the lambda architecture, which combines batch-oriented processing with stream processing to get both low-latency results (potentially inaccurate and incomplete) and results on the full data sets. Instead of scaling batch processing to a point where the latency is small enough, a parallel stream processing layer processes events as they come along, with both routes piping results into a shared database to provide the results for visualization or other kinds of presentation.
Some point out that one problem with this approach is that you potentially need to have all your analytics logic in two distinct, and conceptually quite different systems. But there are systems like Apache Spark, which can run the same code in a batch fashion or near-streaming in micro-batches, or Twitter’s Scalding, which can take the same code to run on Hadoop or Storm.
Others, like Linkedin’s Jay Kreps, ask why you can’t use stream processing also to recompute stuff in batch. Such systems can be implemented by combining a stream processing system with a system like Apache Kafka which is a distributed publish/subscribe event transport layer which doubles as a database for log data by retaining data for a predefined amount of time.
APIs: Functional Collections vs. Actors
These kinds of approaches make you wonder just how interchangable streaming and map-reduce style processing really is, whether it allows you to do the same set of operations. If you think about it, map-reduce is already very stream oriented. In classical Hadoop, both the data input and output to the map and reduce stage is presented via iterators and output pipes, so that you could in principle also stream by the data. In fact, Scalding seems to be taking advantage of exactly that.
Generally, this “functional collection” style APIs seem to become quite popular, as Spark and also systems like Apache Flink use that kind of approach. If you haven’t seen this before, the syntax is very close to the set of operations you have in functional languages like Scala. The basic data type is a collection of objects and you formulate your computations in terms of operations like map, filter, groupby, reduce, but also joins.
This raises the question what exactly streaming analytics is. For some, streaming is any kind of approach which allows you to process data in one go, without the need to go back, and also with more or less bounded resource requirements. Interestingly, this seems to naturally lead to functional collection style APIs, like illustrated in the toolz Python library, although one issue for me here is always that the functional collection style APIs imply that the computation ends at some point, when in reality, it does not.
The other family of APIs uses a more actor-based approach. Stream processing systems like Apache Storm, Apache Samza, or even akka use that kind of approach where you are basically defining worker nodes which take in a stream of data and output another one, and you construct systems by explicitly sending messages asynchronously around between those nodes. In this setting, the on-line nature of the computation is much more explicit.
I personally find actor based approaches always a bit hard to work with mentally, because you have to slice up operations into different actors just to parallelize when conceptually it’s just one step. The functional collection style approach works much better here, however, you then have to rely on the underlying system being able to parallelize your computations well. Systems like Flink take ideas from query optimizations in databases here to attack this problem which I think is a very promising approach.
In general, what I personally would like to see is even more convergence between the functional collection and actor based approaches. I haven’t found too much on that but, to me, that seems like something which is bound to happen.
Data Input and Output
Concerning data input and output, I find it interesting that all of these approaches don’t deal with the question of how to get at the results of your analysis. One of the key features of real-time is that you need to get results as the data comes in, so results have to be continuously updated. This is IMHO also not modelled well in the functional collection style APIs, which imply that the function call returns once the result is computed. Which is never when you process data in an online fashion.
The answer to that solution seems to be to use your highly parallelized, low-latency computation to deal with all the data, but then periodically write out results to some fast, distributed storage layer like a redis database and use that to query the results. It’s generally not possible to access a running stream processing system “from the side” to get at the state which is somewhere distributed in this system. While this approach is possible, it seems to me that it requires you to set up yet another distributed system just to store results.
Concerning data input, there’s of course the usual coverage of all possible kinds of input, from REST, UDP packages, messaging frameworks, log files, and so on. I currently find Kafka quite interesting, because it seems like a good abstraction of combination of a bunch of log files and a log database. You get a distributed set of log data together with the ability to go back in time and replay data. In a way, this is exactly what we had been doing with TWIMPACT when analyzing Twitter data.
Streamdrill
Which brings me back to streamdrill (you knew, this was coming, right?), less because I need to tell you just how great it is, but because it sort of defines where I stand in this landscape myself.
So far, we’ve mainly focussed on the core processing engine. The question of getting the data out has been answered quite differently from the other approaches, as you can directly access the results of your computation by querying the internal state via a REST interface. For getting historical data, you still need to push the data to a storage backend, though. Directly exposing the internal state of the computation is such a big detour from other approaches that I don’t see how you could easily retrofit streamdrill on top of Spark or akka, even though it would be great to get scaling capabilities that way.
I think the most potential for improvement with streamdrill is the part where you encode the actual computation. So far, streamdrill is written and deployed as a more or less classical Jersey webapp, which means that everything is very event-driven. We’re trying to separate functional modules from the REST endpoint code, but still it would need a fair understanding of Java webapps to write anything yourself (and I honestly don’t see data scientists doing that). Here, a more high-level, “functional collection”-style approach would definitely be better.