Stream Processing has no Query Layer
When it comes to real-time big data, stream processing frameworks are an interesting alternative to MapReduce. Instead of storing and crunching data in batches, they process the data as it comes along, which immediately makes much more sense if you’re dealing with event streams. Frameworks like Twitter’s Storm and Yahoo’s S4 allow you to scale such computations. Similar to MapReduce jobs, you specify small worker threads which are then deployed and monitored automatically to provide robust scalability.
So at first you may think “stream processing is basically MapReduce for events”, but there is an important and significant difference: There is no query layer in stream processing (well at least, there isn’t in Storm and S4).
With query layer, I mean the capability to query the results of your computations. For stream processing, in particular, this means while the computations are still running, because you are typically consuming a never-ending stream of new events.
For example, if we consider the ubiquituous word count example, where you pipe in some constant stream of sentences (let’s say, tweets), how can you query the counts for a given word at a given time?
The answer is a bit surprising to most people I’ve talked to: There is no way you can query the result (at least from within the stream processing framework). The information is there, distributed over numerous worker thread who all see and process a part of the stream, but there is no way to access that information. Instead, results have to be periodically output, either to screen or to some persistent storage.
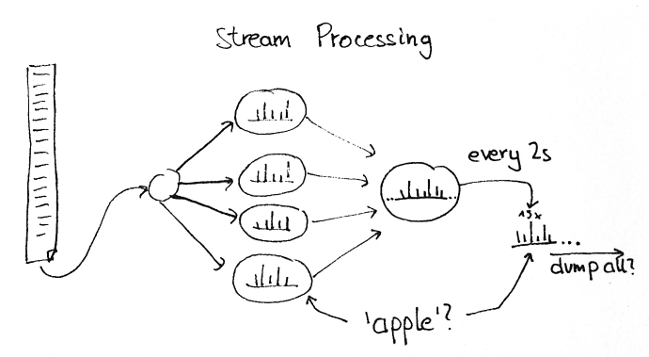
Now these are only toy examples, of course, but it also means that for real-world applications, you need some database backend to store your results. Depending on the amount of data you process and the level of aggregation you do (or don’t do), this also means that your stock MySQL won’t suffice to keep up with your stream processing cluster.
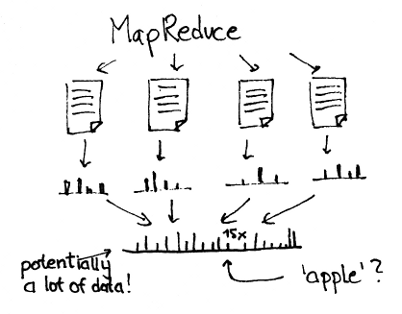
The same can be said of MapReduce jobs which run periodically to update some statistics, but the difference is that MapReduce doubles as the storage solution while you need an additional backend for stream processing.
So I think stream processing is good when:
- you have a high frequency event stream,
- have to do quite complex analyses on each event independently,
- do a lot of aggregation so that there is a huge reduction in data volume.
But it’s not generally applicable when:
- you need to do a lot of persistent updates which each event,
- need to query results while the analysis is still ongoing.
Let me know if I’m wrong. I’d be interested in learning about some real-world experiences with scaling stream processing!
_Edit, Sep 6, 2013:_Shortly after the post I learned about an interesting post by Michael Noll where he explains in detail how to do topic trending over rolling windows with Storm. The implementation shows exactly the level of complexity I was showing above, in particular the need to aggregate trends from the different counter worker threads, and that you can only get the trends if you emit them, and potentially store them somewhere to be queried later.
Big Data beyond MapReduce: Google's Big Data papers
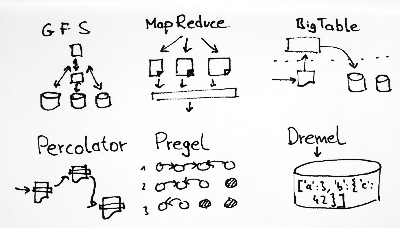
Mainstream Big Data is all about MapReduce, but when looking at real-time data, limitations of that approach are starting to show. In this post, I’ll review Google’s most important Big Data publications and discuss where they are (as far as they’ve disclosed).
MapReduce, Google File System and Bigtable: the mother of all big data algorithms
Chronologically the first paper is on the Google File System from 2003, which is a distributed file system. Basically, files are split into chunks which are stored in a redundant fashion on a cluster of commodity machines (Every article about Google has to include the term “commodity machines”!)
Next up is the MapReduce paper from 2004. MapReduce has become synonymous with Big Data. Legend has it that Google used it to compute their search indices. I imagine it worked like this: They have all the crawled web pages sitting on their cluster and every day or so they ran MapReduce to recompute everything.
Next up is the Bigtable paper from 2006 which has become the inspiration for countless NoSQL databases like Cassandra, HBase, and others. About half of the architecture of Cassandra is modeled after BigTable, including the data model, SSTables, and write-ahead-logs (the other half being Amazon’s Dynamo database for the peer-to-peer clustering model).
Percolator: Handling individual updates
Google didn’t stop with MapReduce. In fact, with the exponential growth of the Internet, it became impractical to recompute the whole search index from scratch. Instead, Google developed a more incremental system, which still allowed for distributed computing.
Now here is where it’s getting interesting, in particular compared to what common messages from mainstream Big Data are. For example, they have reintroduced transactions, something NoSQL still tells you that you don’t need or cannot have if you want to have scalability.
In the Percolator paper from 2010, they describe how the Google is keeping its web search index up to date. Percolator is built on existing technologies like Bigtable, but adds transactions and locks on rows and tables, as well as notifications for change in the tables. These notifications are then used to trigger the different stages in a computation. This way, the individual updates can “percolate” through the database.
This approach is reminiscent of stream processing frameworks (SPFs) like Twitter’s Storm, or Yahoo’s S4, but with an underlying data base. SPFs usually use message passing and no shared data. This makes it easier to reason about what is happening, but also has the problem that there is no way to access the result of the computation unless you manually store it somewhere in the end.
Pregel: Scalable graph computing
Eventually, Google also had to start mining graph data like the social graph in an online social network, so they developed Pregel, published in 2010.
The underlying computational model is much more complex than in MapReduce: Basically, you have worker threads for each node which are run in parallel iteratively. In each so-called superstep, the worker threads can read messages in the node’s inbox, send messages to other nodes, set and read values associated with nodes or edges, or vote to halt. Computations are run till all nodes have voted to halt. In addition, there are also Aggregators and Combiners which compute global statistics.
The paper shows how to implement a number of algorithms like Google’s PageRank, shortest path, or bipartite matching. My personal feeling is that Pregel requires even more rethinking on the side of the implementor than MapReduce or SPFs.
Dremel: Online visualizations
Finally, in another paper from 2010, Google describes Dremel, which is an interactive database with an SQL-like language for structured data. So instead of tables with fixed fields like in an SQL database, each row is something like a JSON object (to be more exact, the data is modeled by Google’s protocol buffer format which imposes restrictions on what fields are allowed). Internally, data is stored in a special format which makes sweeps through the data very efficient. Queries are pushed down to servers and then aggregated on their way back up and use some clever data format for maximum performance.
Big Data beyond MapReduce
Google didn’t stop with MapReduce, but they developed other approaches for applications where MapReduce wasn’t a good fit, and I think this is an important message for the whole Big Data landscape. You cannot solve everything with MapReduce. You can make it faster by getting rid of the disks and moving all the data to in-memory, but there are tasks whose inherent structure makes it hard for MapReduce to scale.
Open source projects have picked up on the more recent ideas and papers by Google. For example, Apache Drill is reimplementing the Dremel framework, while projects like Apache Giraph and Stanford’s GPS are inspired by Pregel.
There are still other approaches as well. I’m personally a big fan of stream mining (not to be confused with stream processing) which aims to process event streams with bounded computational resources by resorting to approximation algorithms. Noel Welsh has some interesting slide’s on the topic.
Related posts:
- One does not simply scale into real-time
- Announcing streamdrill
- More Google Big Data papers: Megastore and Spanner
Edits: Feb 25, 2013 Clarified the Text on Dremel a bit based on Dmitriy Belenko’s comments, corrected post time.
Mar 12, 2013 Added link to follow-up post.
Yet another Big Data whitepaper
I recently read the white paper “Challenges and Opportunities with Big Data” published by the Computing Community Consortium of the CRA. It was an interesting read, but I found it a bit too database centric, which is probably no suprise given its set of authors.
White papers are an interesting class of documents. They’re usually written from a high-level point of view and are often used to represent opinions. I often wonder what their purpose is. At least one is to form a citable piece of authority which others can then use to support whatever agenda they’re up to. For example, McKinsey’s Big Data study is continually cited to say that Big Data will have a huge economic impact in the next years.
The CCC report of course also believes that Big Data is The Next Big Thing, and discusses what it believes are the upcoming challenges. It first defines a Big Data Analysis Pipeline consisting of the steps
- Acquisition/Recording,
- Extraction/Cleaning/Annotation,
- Integration/Aggregation/Representation,
- Analysis/Modeling, and
- Interpretation,
as well as overall properties like Heterogeneity, Scale, Timeliness, Privacy, and Human Collaboration (i.e. cloud sourcing). The report then discusses each of these aspects by giving a brief overview of the state of the art and then discussing future and current challenges.
It becomes pretty clear quickly that most of the authors come from a data base background, because the report outlines an approach similar to what has worked so well in the data base world. Basically, Big Data will be solved by the following two steps:
- Transform raw data into a format which is more suitable for automated analysis, also dealing with noisy or incomplete data.
- Separate the “what” from the “how”, just as a SQL query declaratively says what to compute, leaving it up to the database to break this down into an optimal set of primitive search operations, which we would then know how to scale.
I have my doubts concerning both steps. Don’t get me wrong, having a declarative query language which automatically scales to petabytes of data would be really cool, as well as automated ways to represent data effectively.
But from an ML point of view, data is always noisy and also highly unstructured, in particular in a way we don’t yet know how to interpret automatically. For example, if you take text, it’s pretty clear for us as humans that there is certain information encoded in the text. We have taught computers to understand some of that information using representations like n-grams, some robust form of parsing, and so on, but it is also pretty clear that there is a lot of information we just don’t know how to preserve. In other word, we just don’t know how to preserve the information contained in the data for many media types, and existing techniques will likely destroy a substantial part of that information.
Concerning a declarative query language, I think data base people probably don’t have a good idea of just how divers Machine Learning methods can be. They are inspired by biology, physics, statistics, usually use vectorial representations and linear algebra for computations, or run complex Monte Carlo simulation, all of which cannot be naturally expressed using JOINs and similar things in a relational data base system. So when the report complains that
Today’s analysts are impeded by a tedious process of exporting data from the database, performing a non-SQL process and bringing the data back.
the main reason is that the non-SQL process is so different from a relational world view that this is actually the most effective way to do the computation.
Moreover, ML algorithms are often iterative and have a lot of state, meaning that you don’t just run a query of sorts, but rather complex computations which update a lot of state again and again until your results have converged.
It’s probably possible to build such DSLs for subgroups of algorithms (for example, Bayesian algorithms, distributed linear algebra libraries, etc.), I’m unsure whether there is a general query language which is not just a generic cluster job system. Existing approaches like map reduce or stream processing come with very little assumptions on your data and mostly manage just the parallelization aspect of your computations.
Still, an interesting paper from an infrastructure point of view, but I feel like they’re missing the point when it comes to the data analysis part.