What is streamdrill's trick?
In the previous posts I talked about what streamdrill is good for and how it compares to other Big Data approaches to real-time event processing. Streamdrill solves the top-k problem which consists in aggregating activities in an event stream over different timescales and identifying the most active types of events in real-time.
So, how does streamdrill manage to deal with such large data volumes on a single node?
Streamdrills efficiency is based on two algorithmic choices:
- It uses exponential decay for aggregation.
- It bounds its resource usage by selectively discarding inactive entries.
Let’s take these two things one at a time.
Exponential Decay vs. Exact Time Window
Usually, when you do trending, you aggregate over some fixed time window. The easiest way to do this is to keep counting and reset the counters at a fixed point in time. For example, you could compile daily stats by taking the values at midnight and resetting the counters.
The problem with that approach is that you have to wait for the current interval to end before you have some numbers, which is hardly real-time. You could take the current value of the counter nevertheless and then try to extrapolate in some way, which is also hard if the rate at which events come in varies a lot.
Another approach is to do a “rolling window”, for example, having the counts between now and the the same time yesterday. The problem with that approach is that you need to keep all the data somewhere so that you can subtract an event when it falls out of the window. If you want to aggregate over longer time intervals, say a month, this gets hard, as you have to potentially store millions of events somewhere.
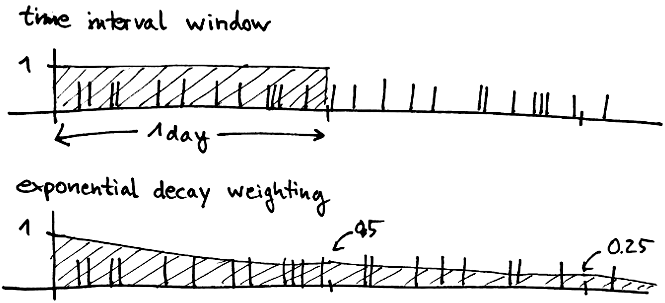
Another approach is to use some form of decay. The idea here is that the “value” of an event decays continually over time until it is eventually zero. That way, you again get an aggregate over some amount of time, although it’s not exactly the same thing as a fixed time window. In the end, it doesn’t really matter if you understand what it is exactly you’re measuring.
The good thing is that decaying counters can often be implemented in a way which does not require us to keep all of the information, but only a few numbers per entry.
Streamdrill does exactly this, using exponential decay. This means that after a specified amount of time, the value of an event has continually reduced to one half, and then again to a quarter, and so on. We chose exponential decay because it has the nice property that a counter always decays to half its original value after a given amount of time, irrespective of the initial value of the counter. That is not the case, for example, for linear decay, where a counter starting at 1000 would take twice as long as one starting at 500.
Keeping resource usage bounded
As I said above, streamdrill throws data away. More specifically, it removes the most inactive entries to make room for new ones. The main purpose of this technique is to ensure that the resource usages of streamdrill are bounded which is important to keep streamdrill’s performance constant.
This is also something we’ve found people having a hard time to digest. After all, isn’t the whole purpose of Big Data to never throw away data?
First of all, note that there really is no way around throwing data away if you want to have a system which runs in a stable manner. Otherwise, data will just accumulate and your system is bound to become slower, unless you are able to grow it. But that costs money and adds a layer of complexity to your system you should not underestimate.
Throwing data for inactive entries away also has the nice effect that you focus on the data which is much more likely to make the top-k entries.
Second of all, as I’ve also discussed in another post, for many applications, in particular if you’re really interested in finding the most active elements, it’s completely ok if you get only approximate results. The counters you get will be approximate, but the overall ranking of the elements will be correct with high probability.
In fact, approximative algorithms are nothing to be afraid of. Approximation algorithms have been around for a long time. For many hard optimization problems, approximative algorithms are the only way we know how to tackle those problems. Such algorithms trade exactness for resource usage, but come with performance guarantees, meaning that if you can afford the computation time or memory usage, you can get the approximation error as small as you wish. The same is true for streamdrill. If you have enough memory to keep all the events, you will get the correct answers.
Streamdrill is even attractive in use cases where you need exact results (for example, in billing), because you can combine it with an (supposedly already existing) batch system, to get real-time analytics without having to invest heavily to scale your batch system to real-time.
So this concludes the mini-series for streamdrill. If you’re interested, head over to streamdrill and download the demo, or contact Leo or me on Twitter, or post your comments and questions below.
We’re currently planning what features to add for the 1.0 version and thinking the details of the licensing model. Currently we’re thinking about both standalone licenses, as well as SaaS-type offerings.
Streamdrill compared to other approaches for the Top-K-Problem
In my last post I’ve discussed what streamdrill does: It solves the top-k problem in real-time which consists in counting activities of different event times over a certain time interval.
So far, so good, but you might wonder why you couldn’t just do this by yourself. After all, it’s just counting, right? Actually, the problem that streamdrill solves is simple, as long as:
- the data volume is small
- the time windows are small compared to the data volume
- the number different kinds of events is small and bounded
- you don’t need the results in real-time
But as soon as you have millions of events per day, wish to aggregate over days, weeks, or even months, and potentially have several million of different types of events, the problem gets quite complicated.
You may end up in such a situation faster than you think:
-
Event rates may rise up beyond what you originally envisioned (in particular if you’re successful. ;-))
-
The number of different event types may explode. This might either be because the underlying sets are already large (say, IP addresses, or users in a social network), or because you are tracking combinations such that the sizes multiply.
Let’s dig deeper into this problem to better understand why this problem quickly gets hard.
One thing you need to keep in mind is that the other solutions we will discuss still involve some amount of coding. So if you compare streamdrill against Hadoop, you would need to do a non-trivial amount of coding for Hadoop, because Hadoop is a general purpose framework taking care of the scaling, but doesn’t solve the top-k problem out of the box.
| streamdrill | Standard SQL | Counters | Stream Processing | |
|---|---|---|---|---|
| solves top-k out of the box | ✓ | ✕ | ✕ | ✕ |
| real-time | ✓ | ✕ | (✓ \$\$\$) | ✓ |
| focusses computation on "hot set" | ✓ | ✕ | ✕ | ✕ |
| memory based for high throughput | ✓ | ✕ | ✕ | ✓ |
| persistent | (✓ ⌚) | ✓ | ✓ | (✓) |
| scales to cluster | (✓ ⌚) | ✕ | ✓ | ✓ |
| exact results | (✓ ⌚) | ✓ | ✓ | ✓ |
✓ = yes, ✕ = no, (✓) = possible, (✓ $$$) = possible, but expensive, (✓ ⌚) = possible, but not yet.
Approach 1: Store and crunch later
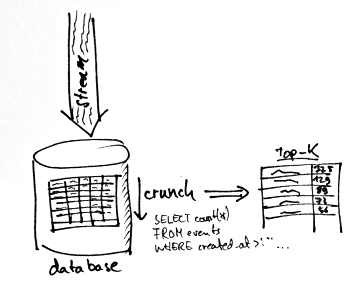
Let’s start by using a traditional approach based on some SQL
database. To do that, you would create a table with a timestamp
column and columns to reflect the fields in your data. Then you would
just pipe in each event into the database. To get the counts you would
run something like SELECT count(*) FROM events WHERE timestamp
> '2012-12-01 00:00' AND timestamp < '2012-12-31 23:59'
potentially also grouping to focus on certain types of events, and
adding an ORDER BY count(*) clause to get the most active
elements.
There a number of problems with this approach:
- If you use a normal disk based database, you will be able to add only a few hundred, at best thousands, events per second,
- As you add more data, your database will become slower over time (and you will be adding a lot of data!). Leo has a number of nice benchmarks on his blog for MongoDB and Cassandra insertion performance.
- Just adding the data is not enough, you also need to crunch the whole data to compute the activities. But the longer the time window, the longer will the query take to run.
- While the query runs, there will be considerable load on your server, making the addition of events even slower.
- Eventually, you will get so slow that your results will already be a few minutes or even hours old once you get them. Hardly real-time.
What’s more, you’re probably only interested in the top 100 active elements, so most of the computation is spent on data you’re not interested in.
In other words, putting the data into some big database and crunching it later won’t really scale. If you’ve got a lot of money on the side, you can employ some form of clustering using map reduce or a similar approach to bring down the times, but the bottom line is the same: You crunch a lot of data which you don’t really need, and the problem will only become harder if you get more and more data. And “harder” also means a lot of coding and operations work (which you don’t have if you just use streamdrill ;)).
Approach 2: Just keeping the counters
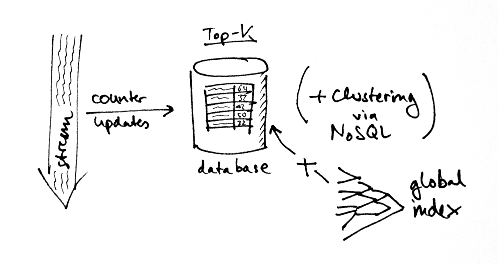
So just storing the data away and crunching it later won’t work. So how about doing the counting on the spot? That way, you wouldn’t have to store all those duplicate events. Note that just keeping the counters isn’t sufficient, you also need to maintain the global index such that you can quickly identify the top-k entries.
Using a complex event processing framework like Esper would also be a way to reduce the coding load, as Esper comes with a nice query language which let’s you formulate averages over time windows in compact way.
Let’s assume your data doesn’t fit into memory anymore (otherwise it won’t be Big Data, right?). One option is to again store the counters in a database. However, just as in the previous example this restricts the number of updates you can handle. Also, you will generate a lot of changes on the database and not all databases handle that amount of write throughput gracefully. For example, Cassandra only marks old entries for deletion and cleans up during the compaction phases. In our experience, such compactions will eventually take hours and put significant load on your system, cutting the throughput in half.
And again, most of the time is spent on elements which will never make the top-k entries.
Approach 3: Stream processing frameworks
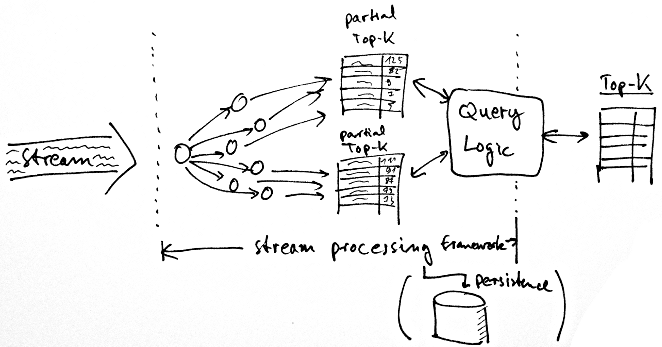
Instead of keeping counters in a database, you could also try and scale out using a stream processing framework like Twitter’s Storm, or Yahoo’s S4. Such systems let you define the computation tasks in the form of small worker threads which are then distributed over a cluster automatically by the framework, also keeping the counters in memory.
While this looks appealing (and in fact, allows you to scale to several hundred thousand events per second), note that this only solves the counting part, but not the global index of all activities. Computing that in a way which scales is non-trivial. You can collect the counter updates at a worker thread which then maintains the index, but what if it doesn’t fit into memory? You could partition the index, but then you’d have to aggregate the data to compute queries, and you’d have to do this yourself, so again, a lot of complexity. The above stream processing frameworks also don’t come with easy support for query, so you’d need to build some infrastructure to collect the results yourself.
And again, you also have a lot of computation for elements which will never show up in your top 100.
In summary
While conceptually simple (in the end, you just count, right), the top-k problem which streamdrill addresses becomes hard if there are more things to count than fit into memory, and the event rate is higher than what you can write to disk.
Finally, let’s discuss some of the differences:
-
As streamdrill is memory based, all the data is lost when streamdrill crashes or is restarted. However, we already have functionality in the engine to write snapshots of all the data, but those aren’t available yet via the API streamdrill.
-
Right now, streamdrill does not support clustering. We just haven’t found it necessary so far, but it’s something that is possible and will be included soon.
-
Finally, as I’m going to explain in more depth in the next post, streamdrill is based on approximate algorithms which trade exactness versus performance. Again, if exactness is really an issue, you can get it by combining with one of the other technologies. This is possible, but not our top priority for now.
In the next post, I’ll explain how streamdrill approaches the problem.
Related posts:
What is streamdrill good for?
A few weeks ago, we released the beta (oh, sorry, the “β”) of streamdrill. One question we heard quite often “Well, what is it good for?” So I’ll try to elaborate a bit more on what it does.
First of all, streamdrill is not yet another general purpose big data framework. In it’s current version it doesn’t even have support for clustering (although that’s something we plan to add in the next months).
In a nutshell: streamdrill is usefull for counting activities of event streams over different time windows and finding the most active ones. For the sake of simplicity, let’s call the above problem the top-k problem.
So let’s break this down a bit.
Event streams are actually common place. Some examples:
- really any kind of server logs
- user interactions in a social network
- logs of web accesses, page impressions, etc.
- monitoring applications of any kind
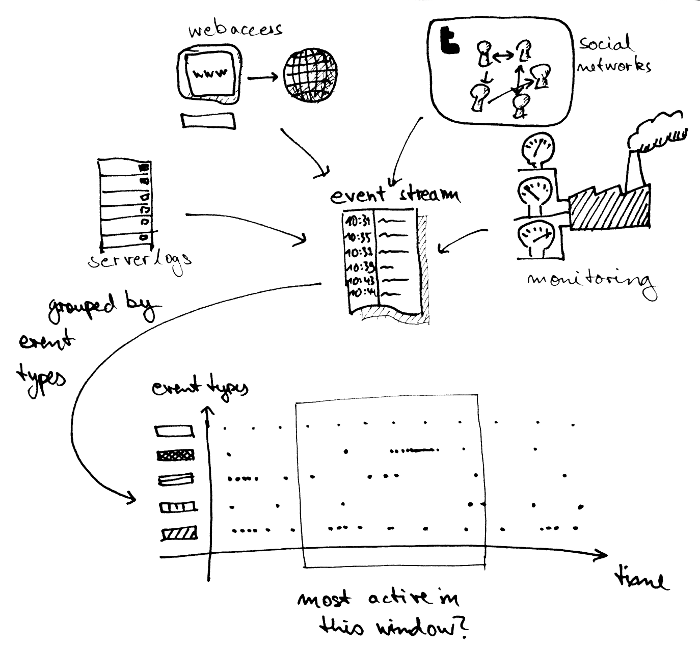
In general, such logs may contain all kinds of data and have varying level of structures, but often it is possible to identify groups of events that have similar structure. For example:
- for server logs: performance reports, errors, exceptions thrown, etc.
- for user interactions: user posting something, user sending messages, etc.
- for web logs: request of page consisting of path, referrer, IP address of the client, user-agent
Such event streams usually contain an enormous amount of data, much too much for a single human being to grasp. As a first step, you’re often interested in doing some kind of aggregation, extracting some basic statistics. For example:
- for server logs: what are the average performances over the last hour on average for the whole cluster? Which exceptions are thrown most often?
- for user interactions: which are the most active users? Which media are trending (i.e. viewed/reshared most often)?
- for web logs: which web pages are viewed most often, from which locations? Who are the most active referrers?
This is exactly what streamdrill does. For a given type of event, it counts activities and aggregates them over time windows. Furthermore, it let’s you filter results so that you can drill down into your trends.
For streamdrill, an event consists of a fixed number of fields (which are called entities). Currently, they are all just plain strings, but this might change in the future.
For every event, you send an update command to streamdrill which then automatically updates the counts for the timescales configured. These timescales aggregate the counters using a technique called exponential decay counters, which is very memory effective. In addition, streamdrill keeps an ordered index of all entries, such that you can quickly query the most active entries, potentially filtering for some of the entities (for example, only show entires for a given path, user-agent, IP address, etc.)
In the next post, we’ll discuss why you would want to use streamdrill for that purpose instead of cooking something up of your own.
Related posts